What Is Serverless Computing? When Should You Use It?
Learn what serverless computing is, how it works, its benefits & drawbacks. Discover when to use serverless architecture and best practices.

Serverless computing has fundamentally transformed how modern organisations build, deploy, and scale cloud applications. Despite its misleading name, serverless architecture doesn’t eliminate servers—instead, it abstracts away infrastructure management, allowing developers to focus entirely on writing code. Cloud providers like AWS, Microsoft Azure, and Google Cloud handle provisioning, maintenance, patching, and scaling, freeing development teams from operational overhead. This paradigm shift represents one of the most significant advances in cloud computing models, enabling organisations to achieve faster time-to-market, reduced costs, and unprecedented scalability.
Serverless computing operates on a pay-as-you-go billing model, where organisations only pay for the computing resources actually consumed rather than pre-provisioned capacity sitting idle. This event-driven architecture approach has become increasingly popular among startups and enterprises alike, with research showing that organisations adopting serverless solutions experience dramatic improvements in development velocity and operational efficiency. Whether you’re building microservices, creating backend services, or processing real-time data, serverless platforms offer a flexible, scalable, and cost-effective alternative to traditional infrastructure management.
What serverless computing truly means and when it’s appropriate to implement is critical for modern software teams. Not every application benefits from a serverless infrastructure, and misapplying this architecture can lead to increased complexity and higher costs than traditional alternatives. This comprehensive guide explores how serverless works, examines serverless benefits and limitations, identifies ideal serverless use cases, and provides actionable guidance for determining whether serverless architecture aligns with your organisation’s needs.
Serverless Computing: Definition and Core Concepts
- Serverless computing represents a cloud service model where the cloud provider manages backend infrastructure entirely, allowing developers to deploy code without provisioning or managing servers. The term can be misleading—while physical servers do exist, developers never interact with them directly. Instead, serverless platforms abstract away infrastructure concerns, enabling development teams to concentrate solely on application logic.
- Function as a Service (FaaS) and Backend as a Service (BaaS) form the foundation of modern serverless architecture. FaaS enables developers to write small, discrete, single-purpose functions that execute in response to specific events. BaaS provides managed backend services like databases, authentication, and APIs. Together, these components create a complete serverless ecosystem that eliminates traditional server management tasks.
- Event-driven architecture powers serverless applications. When an event occurs—a user uploads a file, an API receives a request, or a scheduled time arrives—the serverless platform automatically triggers the corresponding function. Cloud providers allocate compute resources temporarily, execute the code, return the response, and then deallocate resources. This automatic scaling mechanism enables applications to handle anywhere from zero to millions of simultaneous requests without any manual configuration.
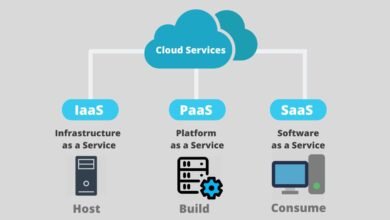
- Serverless infrastructure differs fundamentally from traditional Infrastructure as a Service (IaaS) and Platform as a Service (PaaS) models. With IaaS, organisations purchase and manage virtual machines upfront. PaaS provides more abstraction but still requires manual scaling configuration. Serverless computing takes abstraction further—cloud providers handle provisioning, scaling, maintenance, and capacity planning completely. Developers write functions, deploy them, and the serverless platform handles everything else automatically.
How Serverless Computing Works: The Execution Model
How serverless works clarifies why this architecture offers such compelling advantages for specific use cases. The serverless execution model follows a straightforward sequence: define events, write functions to handle those events, deploy functions to the serverless platform, and let the cloud provider manage everything else.
When a developer deploys a function to a serverless platform like AWS Lambda, the code enters a dormant state, consuming no resources. The function “listens” for triggering events—an HTTP request via API Gateway, a file upload to cloud storage, a database change, a scheduled time interval, or a message in a queue. When an event occurs, the serverless platform immediately provisions a container, loads the function code, executes it, and scales up or down based on incoming event volume.
Automatic scaling represents one of serverless architecture’s most powerful features. A single function can handle one request or one million concurrent requests without code modifications. The serverless platform automatically provisions additional container instances to handle increased load. This dynamic resource allocation ensures applications remain responsive during traffic spikes while incurring zero costs during idle periods—a dramatic contrast to traditional infrastructure, where organisations must purchase capacity for peak demand even during quiet times.
The pay-per-use billing model distinguishes serverless computing from other cloud services. Rather than paying fixed monthly fees for provisioned servers or instances, serverless platforms charge based on actual resource consumption. AWS Lambda, for example, charges based on the number of function invocations and the duration code executes, sometimes breaking billing into 100-millisecond increments. This precision ensures you never pay for idle resources or over-provisioned capacity.
Statelessness characterises serverless functions. Functions should not rely on local storage or maintain state between executions. Instead, state management occurs through external services—databases, caches, message queues, or external APIs. This design principle enables serverless platforms to scale efficiently, instantiating multiple function instances without complex synchronisation mechanisms.
Key Advantages of Serverless Architecture


Serverless computing offers compelling advantages that have driven rapid adoption across industries. These benefits of serverless help explain why development teams increasingly adopt this architecture for new applications.
Cost Efficiency and Reduced Expenses
Cost savings represent one of serverless computing’s most attractive advantages. Organisations eliminate expensive infrastructure investment, no longer purchasing, managing, or maintaining physical servers or paying for idle virtual machine capacity. The pay-as-you-go billing model means you pay only for actual resource consumption—when your code executes. During idle periods, costs drop to zero. For applications with variable or unpredictable workloads, serverless solutions can reduce costs by 50-80% compared to traditional infrastructure.
Automatic Scaling and Elasticity
Automatic scaling eliminates capacity planning—one of the most difficult operational challenges. Serverless platforms monitor incoming requests and instantly provision additional resources without manual intervention or configuration changes. Applications can scale from zero to thousands of concurrent instances within milliseconds. This dynamic scalability ensures consistent performance during traffic spikes, from sudden viral content to seasonal peaks in e-commerce.
Faster Time-to-Market and Development Velocity
Developers eliminate infrastructure management responsibilities, freeing time for building features and improving user experience. Serverless architecture accelerates development cycles—teams deploy code changes within minutes rather than weeks of infrastructure provisioning. This rapid feedback loop enables faster experimentation, quicker bug fixes, and accelerated innovation.
Reduced Operational Complexity
Operational overhead decreases substantially with serverless computing. Cloud providers handle provisioning, patching operating systems, managing security updates, configuring load balancing, monitoring system health, and maintaining availability. Development teams focus exclusively on application code quality, freeing DevOps teams from routine infrastructure maintenance.
Inherent High Availability and Resilience
Serverless platforms provide built-in fault tolerance and redundancy across multiple availability zones. Failed function executions automatically retry, and the cloud provider ensures high availability. Organisations eliminate the complexity of configuring clustering, load balancing, and failover mechanisms—the serverless platform handles this automatically.
Support for Microservices Architecture
Serverless computing enables a microservices architecture, where applications decompose into small, independently deployable services. Each serverless function implements a single business capability, enabling development teams to build, deploy, test, and scale services independently. This approach increases development agility and enables polyglot development—different services written in different programming languages.
Serverless Limitations and Challenges
While serverless computing offers tremendous advantages, significant limitations exist that make it inappropriate for some use cases. Organisations must carefully evaluate serverless disadvantages before committing to this architecture.
Cold Starts and Latency Concerns
- Cold starts represent serverless computing’s primary technical limitation. When a function hasn’t been invoked recently, the serverless platform scales container instances to zero, completely deallocating resources. When the function receives a new request, the platform must provision a fresh container, load code, and initialise the runtime—a process adding 100-500 milliseconds or more latency. For latency-sensitive applications like real-time trading, IoT sensors, or interactive gaming, this cold start delay can be unacceptable.
- Warm starts occur when the container remains provisioned and warm, enabling response times under 1 millisecond. However, functions remain warm only if invoked regularly. Unpredictable traffic patterns mean some requests will inevitably encounter cold start latency.
Vendor Lock-In Risk
Vendor lock-in creates significant switching costs. Each serverless provider (AWS, Azure, Google Cloud) offers unique features, APIs, and service integrations. Code written for AWS Lambda won’t run on Azure Functions without substantial modifications. Migrating applications between providers requires extensive refactoring, making it prohibitively difficult to switch vendors. This dependency on a single cloud provider creates strategic risk if pricing changes unfavorably or service reliability degrades.
State Management Complexity
Serverless functions must be stateless, requiring external services to manage state—databases, caches, queues, or external APIs. Applications that heavily rely on local state or in-memory caching become architecturally complex in serverless environments. This requirement increases operational complexity and introduces additional costs from managing external state stores.
Resource Limitations
Cloud providers impose maximum resource constraints on serverless functions—limits on memory, CPU, runtime duration, and package size. AWS Lambda functions, for example, have maximum execution times (15 minutes), memory allocation limits (10,240 MB), and storage constraints. Applications exceeding these boundaries cannot run on serverless platforms and require traditional servers or containers.
Monitoring and Debugging Complexity
Serverless applications distribute across many stateless, short-lived function instances, making monitoring and debugging substantially more complex than traditional applications. Distributed tracing, logging, and performance monitoring require specialised tools and approaches. Troubleshooting issues becomes time-consuming, requiring analysis across thousands of function invocations and logs.
Limited Infrastructure Control
Serverless computing abstracts away infrastructure entirely, eliminating direct control over runtime environments, operating systems, and server configurations. Organisations cannot install custom software, configure specific kernel parameters, or optimise performance at the infrastructure level. This reduced control makes serverless architecture unsuitable for applications requiring specialised system configuration.
When to Use Serverless Computing: Ideal Use Cases
Serverless computing excels for specific applications and workloads. Knowing when serverless is appropriate prevents costly architectural mistakes.
Event-Driven Applications and Real-Time Processing
Event-driven architectures represent serverless computing’s sweet spot. Applications that respond to discrete events—file uploads, API requests, database changes, or IoT sensor data—benefit tremendously. Serverless functions execute only when triggered, scaling automatically with event volume. Real-time data processing, stream processing, and event transformations execute efficiently and cost-effectively.
Microservices and APIs
Microservices architectures naturally align with serverless computing. Each serverless function implements a single business capability, enabling independent development, testing, and deployment. API backends built on serverless functions scale automatically with request volume, eliminating the need to provision capacity for peak demand. This approach works particularly well for APIs with variable traffic patterns.
Data Processing and Transformation
Batch processing and data transformation tasks execute efficiently on serverless platforms. Image resizing, video transcoding, data format conversion, and ETL operations trigger automatically when new files arrive, executing in parallel across many function instances. Organisations pay only for actual processing time, making serverless data processing cost-effective even for compute-intensive workloads.
IoT Applications and Sensor Data Processing
Internet of Things (IoT) applications generate continuous sensor data that requires processing. Serverless functions process IoT events, extract relevant data, trigger alerts, and update databases. The automatic scaling and event-driven model make serverless platforms ideal for IoT backends that experience unpredictable traffic patterns as millions of devices send data.
Scheduled Tasks and Batch Jobs
Background jobs triggered on schedules—daily reports, periodic data cleanup, weekly analytics—run efficiently on serverless platforms. CloudWatch Events, EventBridge, or scheduler services trigger serverless functions at specified times. Organisations avoid maintaining always-on servers for tasks running for minutes daily.
Chatbots and Interactive Applications
Chatbot applications responding to user messages execute naturally on serverless platforms. Each user message triggers a serverless function that processes the request and generates a response. Automatic scaling ensures the chatbot remains responsive regardless of user volume, while pay-per-use billing means costs scale proportionally with user engagement.
When NOT to Use Serverless Computing
Equally important is when serverless architecture introduces unnecessary complexity or cost.
Long-Running Applications and Persistent Workloads
Applications requiring sustained execution—long-running batch processes, continuous monitoring, or persistent background jobs—don’t align with serverless computing. Serverless functions typically have maximum execution durations (e.g., 15 minutes for AWS Lambda), and charges accumulate for long-running functions. Traditional servers or container orchestration platforms cost less for continuously running workloads.
Consistent, Predictable Traffic
Applications experiencing consistent, predictable traffic may cost more on serverless platforms than traditional servers. If your application continuously runs at full capacity, pre-provisioned infrastructure often costs less than paying for individual function invocations. Calculate actual costs before committing to serverless architecture for applications with steady-state traffic.
Complex Stateful Applications
Applications maintaining complex state in local memory, relying on local caching, or requiring session persistence become architecturally complex in serverless environments. While serverless functions can manage state through external services, the added complexity often makes traditional architecture more practical.
Real-Time, Latency-Critical Applications
Applications requiring response times under 100 milliseconds may suffer from cold start latency. Real-time trading platforms, multiplayer gaming servers, and low-latency IoT applications often require guaranteed response times that serverless computing cannot reliably provide.
High-Performance Computing and GPU Workloads
Serverless platforms aren’t optimised for compute-intensive workloads requiring GPU acceleration or specialised hardware. Machine learning training, scientific simulations, and graphics rendering execute more efficiently on bare metal or GPU-equipped servers than serverless functions.
Popular Serverless Platforms and Providers
Multiple cloud providers offer serverless computing services with varying features and capabilities.
AWS Lambda
AWS Lambda pioneered serverless computing and remains the market leader. Lambda functions support multiple programming languages (Python, Node.js, Java, Go, Ruby, and… NET) and integrate with over 200 AWS services. The pay-per-use billing model charges per 100 milliseconds of execution time. AWS Lambda’s extensive ecosystem, broad integration capabilities, and mature tooling make it the default choice for many organisations.
Microsoft Azure Functions
Azure Functions provides serverless computing on the Microsoft platform, supporting multiple languages and integrating with Azure services. Azure serverless offers flexible consumption plans and premium plans, accommodating different cost and performance requirements.
Google Cloud Functions
Google Cloud Functions provides event-driven serverless computing on Google’s infrastructure. Integrated with Google’s machine learning and data analytics services, Google Cloud Functions appeals to organisations already leveraging Google Cloud services.
Cloudflare Workers
Cloudflare Workers executes serverless functions at the network edge, near end users, dramatically reducing latency. Written in JavaScript, Cloudflare Workers suits applications prioritising performance and global distribution.
Serverless Computing Best Practices and Implementation Strategies
Successfully implementing serverless architecture requires following established best practices and patterns.
Design Stateless, Single-Purpose Functions
Function design should prioritise simplicity and single responsibility. Each serverless function should perform one task, accepting input and returning output without maintaining state. Larger, monolithic functions become difficult to debug, scale, and maintain.
Manage State Externally
Store application state in dedicated services—databases, caches, message queues, or external APIs. Never rely on local filesystem state or in-memory variables between function invocations. External state management enables serverless platforms to instantiate and destroy function instances dynamically.
Implement Comprehensive Monitoring and Logging
Deploy robust observability infrastructure using CloudWatch, Datadog, New Relic, or similar platforms. Track function execution duration, error rates, cold start frequency, and resource utilisation. Detailed logging from every function enables rapid troubleshooting and performance optimisation.
Use Connection Pooling and Resource Optimisation
Serverless functions share infrastructure, making resource efficiency critical. Implement database connection pooling, reuse HTTP clients, and minimise package sizes. Optimise memory allocation using tools like AWS Lambda Power Tuning to balance cost and performance.
Implement Proper Error Handling and Retry Logic
Build resilient serverless applications with comprehensive error handling, exponential backoff, and retry mechanisms. Configure dead letter queues for failed processing, ensuring no events are lost silently.
Leverage Managed Services and Integration Patterns
Maximise cloud provider services designed for serverless applications—message queues, databases, API gateways, and notification services. These managed services integrate seamlessly and eliminate infrastructure management.
Cost Optimisation Strategies for Serverless Applications

Achieving cost efficiency requires serverless billing and implementing optimisation strategies.
Right-Size Memory Allocation
Memory allocation impacts both cost and performance. Serverless platforms charge based on the memory allocated. Test different memory configurations to find the optimal balance—more memory enables faster code execution, but increases per-millisecond costs.
Eliminate Unnecessary Function Invocations
Batch event processing, deduplicate requests, and filter upstream events to minimise unnecessary function invocations. Each invocation incurs cost, so reducing invocation frequency directly reduces expenses.
Optimise Code Execution Time
Write efficient code, eliminate unnecessary operations, and leverage built-in optimisation tools. Faster execution means lower duration charges. Profile code regularly to identify and eliminate performance bottlenecks.
Use Reserved Capacity Wisely
Some serverless providers offer reserved capacity options, providing discounts for guaranteed minimum usage. For applications with predictable baselines, reserved capacity can reduce costs significantly.
Monitor and Alert on Costs
Enable detailed cost tracking and set up alerts for unexpected cost spikes. Serverless billing precision means small inefficiencies compound quickly. Regular cost reviews identify optimisation opportunities.
The Future of Serverless Computing
Serverless architecture continues evolving rapidly, with emerging trends reshaping the landscape.
Container Integration and Knative
Containerization and serverless are converging. Knative and AWS Fargate enable running containerised workloads in serverless mode, combining container flexibility with serverless cost-efficiency. This hybrid approach expands serverless computing’s applicability.
Edge Computing and Distributed Execution
Serverless functions increasingly execute at network edges, closer to end users. Cloudflare Workers and similar edge platforms reduce latency while improving global performance. Edge-native serverless architecture will become increasingly prevalent.
Serverless Databases and Data Processing
Serverless databases like Amazon Aurora Serverless and Google Cloud Spanner automatically scale capacity, eliminating database management. Serverless data processing services handle analytics, machine learning inference, and data transformation without infrastructure provisioning.
Event-Driven AI and Machine Learning
Serverless platforms increasingly support machine learning inference and AI model deployment. Event-driven AI applications trigger machine learning functions in response to data, enabling intelligent automation at scale.
More Read: What Is Spatial Computing and Should You Care?
Conclusion
Serverless computing represents a fundamental shift in how organisations build and deploy cloud applications, offering unprecedented scalability, cost efficiency, and development velocity. Rather than managing infrastructure, developers focus entirely on writing code, while cloud providers handle provisioning, scaling, and maintenance. The event-driven architecture and pay-per-use billing model make serverless platforms ideal for microservices, APIs, data processing, IoT backends, and event-driven applications with variable traffic patterns.
However, serverless computing isn’t a universal solution—long-running applications, latency-critical systems, and workloads with constant demand may cost more or perform worse than traditional infrastructure. Success requires careful evaluation of your specific use cases, when serverless applies and when alternative architectures make sense. Organisations that thoughtfully apply serverless architecture to appropriate workloads, implement best practices for design and monitoring, and optimise for costs, unlock tremendous competitive advantages.
As serverless technology continues maturing, with improved cold start performance, expanded platform capabilities, and emerging edge computing options, adoption will accelerate across industries. The future of cloud computing is unquestionably serverless-first—organisations embracing this architecture today position themselves to build faster, scale better, and compete more effectively tomorrow.