Machine Learning Data Preprocessing Best Practices Guide
Master machine learning data preprocessing with proven techniques, best practices, and expert tips for optimal model performance
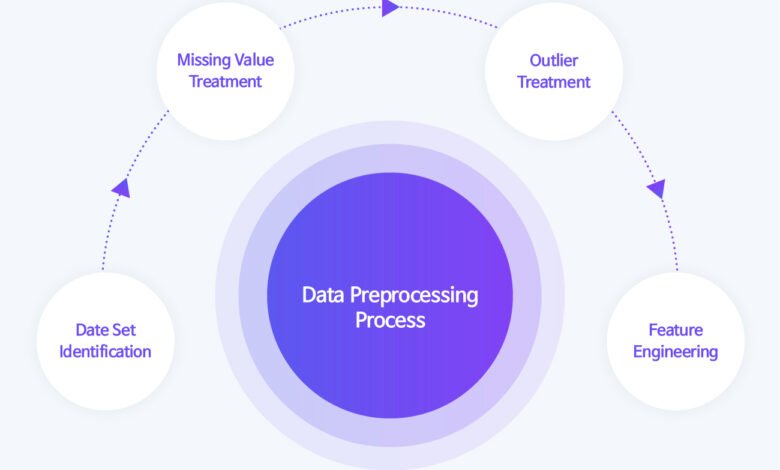
Machine learning data preprocessing represents the cornerstone of successful artificial intelligence projects, transforming raw, unstructured data into clean, analyzable formats that algorithms can effectively process. In today’s data-driven landscape, where organizations generate massive volumes of information daily, the quality of your data preprocessing directly determines the success of your machine learning models.
The significance of Machine Learning Data Preprocessing cannot be overstated. Research indicates that data scientists spend approximately 80% of their time on data preparation tasks, highlighting the critical importance of mastering these fundamental techniques. Without proper preprocessing techniques, even the most sophisticated algorithms will produce unreliable results, leading to poor model performance and incorrect predictions.
Data preprocessing best practices encompass a comprehensive range of activities, from handling missing values and removing duplicates to feature scaling and data transformation. These processes ensure that your datasets meet the specific requirements of machine learning algorithms while maintaining data integrity and statistical validity. Modern preprocessing pipelines have evolved to include automated tools and frameworks that streamline these traditionally time-consuming tasks.
The landscape of Machine Learning Data Preprocessing continues to evolve with advancing technologies. Feature engineering, data cleaning, and normalization techniques have become increasingly sophisticated, enabling data scientists to extract maximum value from complex datasets. These methodologies are essential for anyone working with supervised learning, unsupervised learning, or deep learning applications.
This comprehensive guide explores proven data preprocessing strategies that industry professionals use to optimize model performance. We’ll examine everything from basic data cleaning techniques to advanced feature selection methods, providing practical insights for implementing robust ML data preprocessing workflows that scale with your organization’s growing data needs.
Machine Learning Data Preprocessing Fundamentals
Machine Learning Data Preprocessing forms the foundation of every successful machine learning project, serving as the critical bridge between raw data and actionable insights. This fundamental process involves systematically preparing, cleaning, and transforming datasets to meet the specific requirements of machine learning algorithms.
What is Data Preprocessing
Machine learning data preprocessing encompasses all activities required to convert raw, unstructured data into a clean, consistent format suitable for algorithm training. This process addresses common data quality issues such as missing values, inconsistent formatting, duplicate records, and outliers that can significantly impact model performance.
The preprocessing pipeline typically involves multiple sequential steps, each designed to address specific data quality challenges. These steps ensure that your machine learning models receive high-quality input data, leading to more accurate predictions and reliable results.
Core Components of Machine Learning Data Preprocessing
Data transformation represents one of the most critical aspects of preprocessing, involving the conversion of data from one format to another. This includes normalization, standardization, and encoding categorical variables to ensure compatibility with machine learning algorithms.


Feature engineering extends beyond basic transformation to create new, meaningful variables that better represent underlying patterns in your data. This process often involves domain expertise to identify relationships between variables that aren’t immediately apparent in the raw dataset.
Data validation ensures that processed data meets quality standards and maintains consistency throughout the preprocessing pipeline. This includes checking for data types, value ranges, and logical relationships between variables.
Essential Data Cleaning Techniques
Data cleaning represents the most time-intensive aspect of Machine Learning Data Preprocessing, often consuming 60-80% of the total project timeline. Effective data cleaning techniques ensure that your datasets are free from errors, inconsistencies, and anomalies that could compromise model performance.
Handling Missing Data
Missing data handling requires careful consideration of the underlying reasons for data absence. Imputation techniques such as mean substitution, median replacement, or forward-fill methods can effectively address numerical gaps, while categorical variables may require mode imputation or advanced techniques like K-nearest neighbors imputation.
Advanced missing data strategies include predictive imputation using machine learning algorithms to estimate missing values based on other variables in the dataset. This approach often produces more accurate results than simple statistical replacements.
Removing Duplicates and Outliers
Duplicate removal involves identifying and eliminating redundant records that can skew statistical analysis and model training. Modern preprocessing tools provide automated duplicate detection based on exact matches or similarity thresholds.
Outlier detection requires statistical techniques such as z-score analysis, interquartile range methods, or isolation forests to identify data points that significantly deviate from normal patterns. The treatment of outliers depends on their nature – some may represent valuable edge cases while others indicate data collection errors.
Data Type Optimization
Data type conversion ensures that variables are stored in appropriate formats for efficient processing and analysis. Converting strings to numerical values, optimizing integer sizes, and handling date-time formats properly can significantly improve processing speed and memory usage.
Feature Engineering and Selection Strategies
Feature engineering transforms raw variables into meaningful predictors that enhance model performance and interpretability. This creative process combines domain knowledge with statistical techniques to extract maximum value from available data.
Creating New Features
Feature creation involves generating new variables through mathematical operations, combinations of existing features, or the extraction of temporal patterns. Common techniques include polynomial features, interaction terms, and binning continuous variables into categorical groups.
Temporal feature extraction proves particularly valuable for time-series data, creating features such as day of week, seasonality indicators, and rolling averages that capture important temporal patterns.
Feature Selection Methods
Feature selection reduces dimensionality by identifying the most relevant variables for model training. Statistical feature selection methods include correlation analysis, chi-square tests, and mutual information scores to quantify relationships between features and target variables.
Machine learning-based feature selection techniques such as recursive feature elimination, LASSO regularization, and tree-based feature importance provide automated approaches to identifying optimal feature subsets.
Dimensionality Reduction
Principal component analysis (PCA) and t-distributed stochastic neighbor embedding (t-SNE) offer powerful techniques for reducing dataset complexity while preserving essential information. These methods prove particularly valuable for high-dimensional datasets where visualization and computational efficiency are important considerations.
Data Transformation and Normalization
Data transformation ensures that variables are properly scaled and distributed for optimal algorithm performance. Different machine learning algorithms have specific requirements for data formats and scales, making transformation a critical preprocessing step.
Scaling Techniques
Feature scaling addresses the challenge of variables with different units and ranges that could bias algorithm performance. Min-max normalization scales features to a fixed range (typically 0-1), while z-score standardization transforms variables to have zero mean and unit variance.
Robust scaling methods use median and interquartile range instead of mean and standard deviation, providing better handling of outliers. The choice of scaling method depends on data distribution characteristics and algorithm requirements.
Encoding Categorical Variables
Categorical encoding converts non-numeric variables into formats suitable for machine learning algorithms. One-hot encoding creates binary columns for each category, while label encoding assigns numerical values to categories.
Advanced encoding techniques include target encoding, which replaces categories with their mean target values, and hash encoding, which handles high-cardinality categorical variables efficiently.
Log and Power Transformations
Log transformations help normalize skewed distributions and stabilize variance, particularly useful for financial and biological data. Box-Cox transformations provide a more flexible approach to achieving normality through optimal power parameter selection. These transformations can significantly improve model performance, especially for algorithms that assume normally distributed data.
Automated Preprocessing Tools and Frameworks
Modern preprocessing automation tools streamline data preparation workflows, reducing manual effort and improving consistency across projects. These frameworks integrate seamlessly with popular machine learning libraries and provide robust, scalable solutions for complex preprocessing tasks.
Popular Preprocessing Libraries
Scikit-learn preprocessing modules offer comprehensive tools for scaling, encoding, and transformation tasks. The library’s Pipeline class enables the creation of reproducible preprocessing workflows that can be easily applied to new datasets.
Pandas provides powerful data manipulation capabilities, including built-in functions for handling missing data, duplicate removal, and data type conversions. Its integration with other Python libraries makes it an essential tool for data wrangling.
AutoML Preprocessing Solutions
Automated machine learning (AutoML) platforms incorporate intelligent preprocessing capabilities that adapt to dataset characteristics automatically. Tools like H2O AutoML, AutoKeras, and TPOT can identify optimal preprocessing steps through systematic experimentation. These platforms use meta-learning approaches to apply successful preprocessing strategies from similar datasets, reducing the need for manual tuning and domain expertise.
Cloud-Based Preprocessing Services
Cloud preprocessing services from providers like AWS SageMaker, Google Cloud AI Platform, and Azure Machine Learning offer scalable solutions for large dataset processing. These services provide managed infrastructure and pre-built preprocessing components.
Serverless preprocessing architectures enable cost-effective processing of variable workloads without infrastructure management overhead.
Handling Different Data Types
Multi-modal Machine Learning Data Preprocessing requires specialized techniques for different data formats, each presenting unique challenges and opportunities for feature extraction and analysis.
Text Data Preprocessing
Natural language processing (NLP) preprocessing involves tokenization, stop word removal, stemming, and lemmatization to prepare text for analysis. Text vectorization techniques such as TF-IDF, word embeddings, and transformer models convert textual content into numerical representations. Advanced text preprocessing includes handling special characters, normalizing case, and dealing with different languages and encoding standards.
Image Data Preprocessing
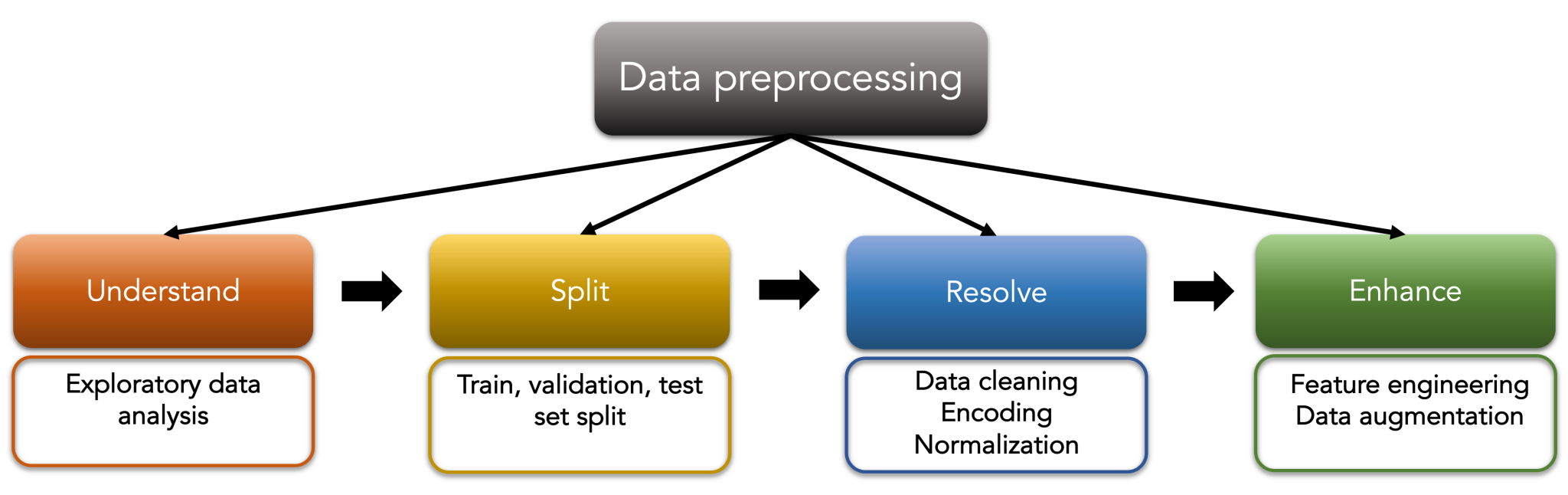
Computer vision preprocessing encompasses image resizing, normalization, and augmentation techniques that improve model robustness and generalization. Data augmentation strategies include rotation, flipping, and color adjustments that artificially expand training datasets.
Image normalization typically involves scaling pixel values to standard ranges and applying mean subtraction to center the data distribution.
Time Series Machine Learning Data Preprocessing Data Preprocessing
Time series preprocessing addresses challenges such as irregular sampling intervals, seasonal patterns, and trend removal. Resampling techniques standardize temporal resolution, while detrending and seasonal decomposition isolate underlying patterns.
Feature engineering for time series includes creating lagged variables, rolling statistics, and seasonal indicators that capture temporal dependencies.
Quality Assurance and Validation
Data quality assurance ensures that preprocessing steps maintain data integrity while achieving desired transformation objectives. Comprehensive validation procedures prevent preprocessing errors from propagating to model training stages.
Data Profiling and Exploration
Exploratory data analysis (EDA) provides crucial insights into data distribution, correlation patterns, and potential quality issues. Statistical summaries, visualization techniques, and correlation analysis help identify preprocessing requirements and validate transformation results.
Data profiling tools automatically generate comprehensive reports on data characteristics, including missing value patterns, distribution shapes, and potential outliers.
Preprocessing Pipeline Testing
Pipeline validation involves systematic testing of preprocessing steps to ensure reproducibility and correctness. Unit testing frameworks can validate individual preprocessing functions, while integration testing verifies end-to-end pipeline behavior.
Cross-validation techniques help assess the impact of preprocessing choices on model performance, enabling data-driven optimization of preprocessing parameters.
Monitoring and Maintenance
Production preprocessing monitoring tracks data quality metrics and preprocessing performance over time. Data drift detection identifies changes in input data characteristics that may require preprocessing pipeline updates.
Version control for preprocessing pipelines ensures reproducibility and enables rollback capabilities when issues arise in production environments.
Performance Optimization Strategies
Machine Learning Data Preprocessing performance optimization becomes critical when working with large datasets or real-time processing requirements. Efficient algorithms and computational strategies can dramatically reduce processing time and resource consumption.
Memory-Efficient Processing
Chunked processing techniques enable the handling of datasets larger than available memory by processing data in smaller batches. Streaming preprocessing approaches process data incrementally, reducing memory requirements and enabling real-time applications.
Memory mapping and lazy evaluation strategies defer computation until results are actually needed, optimizing resource usage for complex preprocessing pipelines.
Parallel Processing Techniques
Distributed preprocessing leverages multiple CPU cores or computing nodes to accelerate data transformation tasks. Apache Spark and Dask provide powerful frameworks for scaling preprocessing operations across clusters.
GPU acceleration can dramatically speed up certain preprocessing operations, particularly for image and numerical data transformations.
Caching and Incremental Updates
Preprocessing caching stores intermediate results to avoid redundant computations when processing similar datasets or iterating on preprocessing parameters. Incremental preprocessing updates only changed portions of datasets, reducing computational overhead for routine data updates.
Checkpointing mechanisms enable recovery from processing failures without restarting entire preprocessing workflows.
Common Pitfalls and How to Avoid Them
Preprocessing mistakes can significantly impact model performance and lead to incorrect conclusions. Common pitfalls help data scientists avoid costly errors and implement more robust preprocessing workflows.
Data Leakage Prevention
Data leakage occurs when future information inadvertently influences preprocessing steps, leading to overly optimistic model performance estimates. Temporal leakage in time series data and target leakage in feature engineering represent particularly dangerous forms of this problem. Proper train-test splitting before preprocessing and careful feature engineering practices help prevent leakage issues.
Overfitting in Preprocessing
Preprocessing overfitting happens when transformation parameters are optimized too specifically for training data, reducing the model’s generalization ability. Parameter fitting should only use training data, with validation and test sets processed using pre-fitted parameters.
Cross-validation during preprocessing parameter selection helps identify robust transformation strategies that generalize well to new data.
Bias Introduction
Preprocessing bias can inadvertently introduce systematic errors that affect model fairness and accuracy. Sampling bias, selection bias, and measurement bias can all be amplified during preprocessing if not carefully managed. Regular bias audits and fairness assessments help identify and mitigate these issues before they impact model deployment.
More Read: Supervised vs Unsupervised Machine Learning Complete Comparison
Conclusion
Machine learning data preprocessing represents a critical foundation for successful AI projects, requiring mastery of diverse techniques from basic data cleaning to advanced feature engineering. The comprehensive best practices outlined in this guide provide a roadmap for implementing robust preprocessing pipelines that enhance model performance and ensure reliable results.
As automated preprocessing tools continue to evolve, practitioners must balance efficiency gains with the need for domain expertise and quality validation. Success in data preprocessing ultimately depends on your specific dataset characteristics, algorithm requirements, and business objectives, while maintaining rigorous standards for data quality and preprocessing validation. By following these proven strategies and avoiding common pitfalls, data scientists can build preprocessing workflows that scale effectively and deliver consistent value across diverse machine learning applications.