How to Build Your First Machine Learning Model Step by Step
Learn how to build your first machine learning model with our comprehensive step-by-step guide. Master data preparation, algorithms
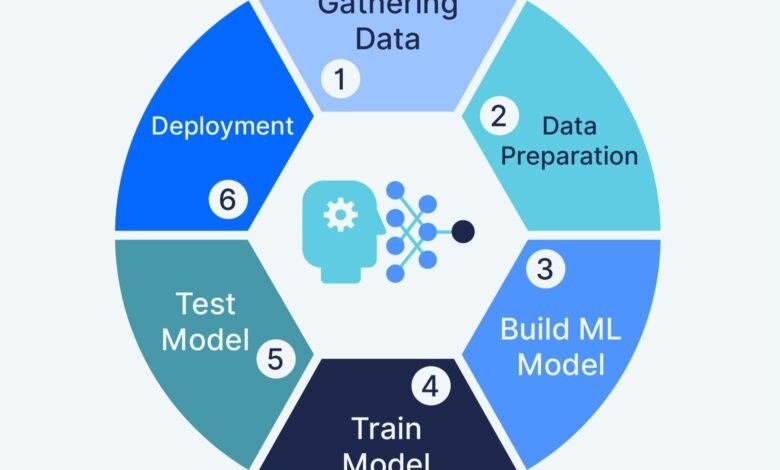
Building your first machine learning model represents a transformative milestone in any aspiring data scientist’s journey. The process might initially seem daunting, filled with complex algorithms, mathematical equations, and programming challenges. However, with the right guidance and a systematic approach, creating a machine learning model becomes an accessible and rewarding endeavor that opens doors to countless opportunities in artificial intelligence and data science.
Machine learning has revolutionized industries ranging from healthcare and finance to entertainment and e-commerce. Every recommendation you receive on Netflix, every personalized advertisement you see online, and every voice command processed by your smartphone involves sophisticated machine learning algorithms working behind the scenes. How to build machine learning models empowers you to contribute to this technological revolution and solve real-world problems using data-driven insights.
This comprehensive guide will walk you through the entire machine learning process, from fundamental concepts to deploying your first working model. Whether you’re a complete beginner or someone with basic programming knowledge looking to venture into artificial intelligence, this tutorial provides practical, actionable steps that demystify the machine learning model development process.
Throughout this article, you’ll discover how to prepare your training data, select appropriate algorithms, implement data preprocessing techniques, evaluate model performance, and deploy your creation for real-world applications. We’ll focus on practical implementation using Python and popular machine learning libraries like Scikit-learn, ensuring you gain hands-on experience while building your first predictive model.
The journey to mastering machine learning begins with a single model, and by the end of this guide, you’ll possess the knowledge and confidence to create your own supervised learning or unsupervised learning solutions. Let’s embark on this exciting adventure into the world of data science and artificial intelligence, transforming you from a curious learner into a capable machine learning practitioner.
Machine Learning Fundamentals
Before diving into building your first machine learning model, it’s essential to grasp the foundational concepts that underpin this transformative technology. Machine learning is a subset of artificial intelligence that enables computers to learn from data and improve their performance without being explicitly programmed for every specific task.
What is a Machine Learning Model
A machine learning model is essentially a mathematical representation of a real-world process, created by analyzing patterns within training data. Think of it as a sophisticated pattern-recognition system that learns from examples rather than following rigid, pre-programmed rules. When you build a machine learning model, you’re teaching a computer to make predictions or decisions based on historical information.
Machine learning models come in various types, each suited for different problems. Supervised learning models learn from labeled data where the correct answers are provided during training. Unsupervised learning models discover hidden patterns in unlabeled data. Reinforcement learning models learn through trial and error, receiving rewards for correct actions.
Key Components of Machine Learning
The essential building blocks help you effectively create machine learning models. The primary components include:


Data: The foundation of any machine learning project. Your dataset must be relevant, sufficient, and representative of the problem you’re solving. Quality data directly impacts model accuracy and performance metrics.
Features: These are the individual measurable properties or characteristics in your dataset. Feature engineering and feature selection are crucial steps in the machine learning pipeline that significantly influence your model’s predictive power.
Algorithms: The mathematical procedures that enable machine learning models to learn patterns. Popular algorithms include Linear Regression, Decision Trees, Random Forest, Support Vector Machines, and Neural Networks.
Training: The process by which your machine learning model learns from training data by adjusting its internal parameters to minimize prediction errors. This phase involves hyperparameter tuning and optimization techniques.
Setting Up Your Development Environment
Creating the proper machine learning development environment is your first practical step toward building your first model. A well-configured setup ensures smooth workflow and access to essential machine learning libraries and tools.
Installing Python and Essential Libraries
Python has emerged as the dominant programming language for machine learning and data science due to its simplicity, readability, and extensive ecosystem of specialized libraries. To build machine learning models, you’ll need several core Python libraries:
NumPy: Provides support for large, multi-dimensional arrays and matrices, along with mathematical functions to operate on these arrays. It’s fundamental for numerical computing in machine learning.
Pandas: Offers powerful data structures and data analysis tools, making data manipulation and preprocessing significantly easier. It’s invaluable for handling datasets in various formats.
Scikit-learn: The most popular machine learning library for Python, containing implementations of numerous machine learning algorithms, data preprocessing tools, model evaluation metrics, and utilities for model selection.
Matplotlib and Seaborn: Visualization libraries essential for exploratory data analysis, your dataset, and presenting model performance results through compelling graphics.
Install these libraries using pip:
pip install numpy pandas scikit-learn matplotlib seaborn
Choosing Your IDE
Selecting the right Integrated Development Environment (IDE) enhances productivity when you build machine learning models. Jupyter Notebook is excellent for beginners, offering an interactive environment where you can write code, visualize results, and document your machine learning process in a single interface. Alternatives include PyCharm, Visual Studio Code, and Google Colab for cloud-based development.
Step 1: Define Your Problem and Gather Data
Every successful machine learning project begins with clearly defining the problem you want to solve. This foundational step determines your approach, algorithm selection, and evaluation criteria.
Identifying the Problem Type
Machine learning problems generally fall into several categories. Classification problems involve predicting discrete categories (like spam detection or disease diagnosis). Regression problems predict continuous values (such as house prices or stock market trends). Clustering problems group similar data points without predefined labels.
Your problem type guides your algorithm choice and model evaluation strategy. For your first machine learning model, start with a straightforward classification or regression problem with readily available datasets.
Collecting and Your Dataset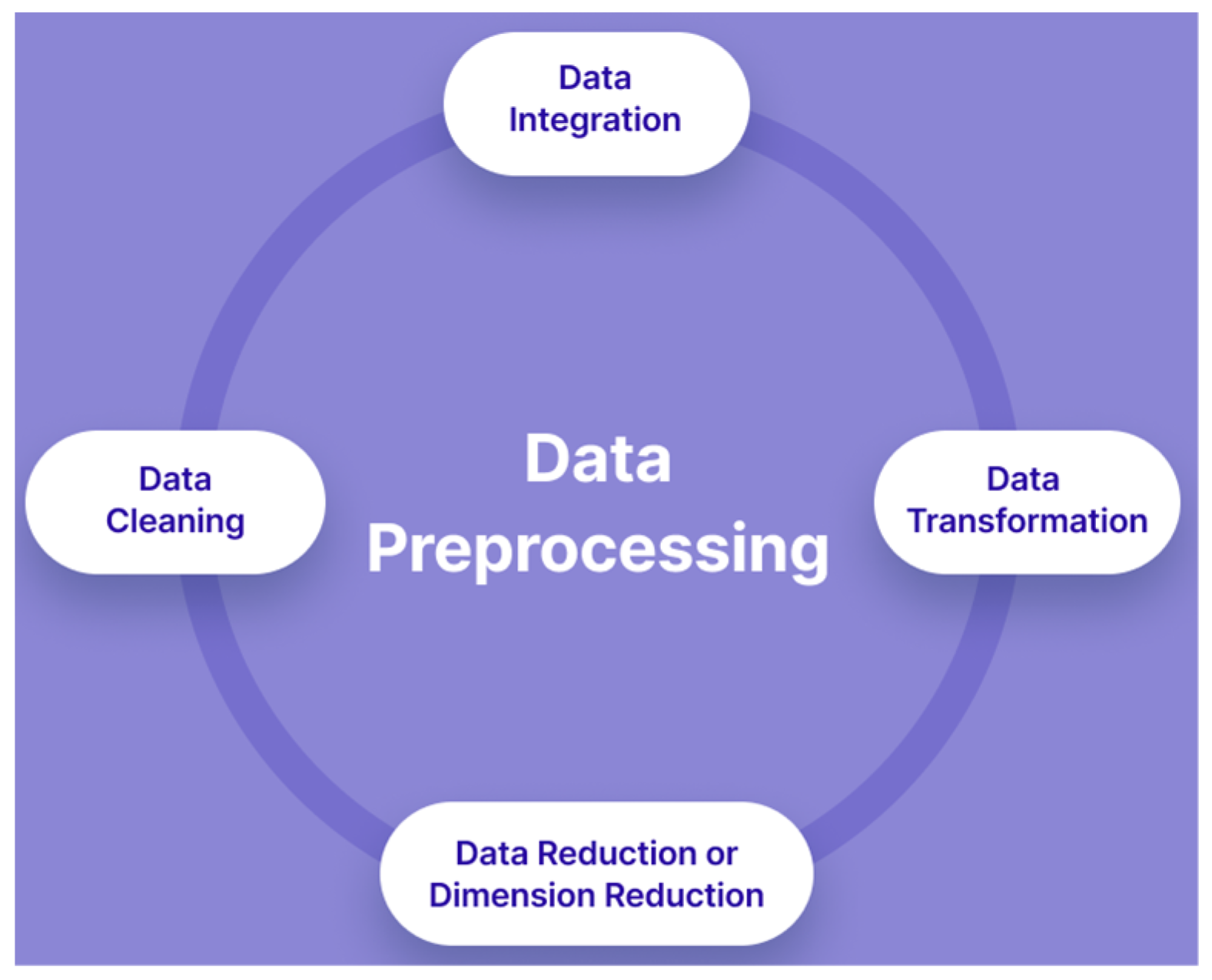
Quality data is the lifeblood of machine learning. Your dataset should be relevant, sufficient in quantity, and representative of real-world scenarios. For beginners, publicly available datasets from repositories like Kaggle, UCI Machine Learning Repository, or Scikit-learn’s built-in datasets provide excellent starting points.
When gathering data, consider:
Data Volume: More training data generally improves model performance, but quality trumps quantity. Aim for thousands of examples when building your first model.
Data Diversity: Your dataset should represent various scenarios your model will encounter in production. Biased or limited data leads to poor generalization.
Feature Relevance: Ensure your dataset contains features that logically relate to your prediction target. Irrelevant features introduce noise and complicate model training.
Exploratory Data Analysis
Before building your machine learning model, perform thorough exploratory data analysis (EDA). This process involves data distributions, identifying patterns, detecting outliers, and visualizing relationships between features. Use Pandas for statistical summaries and Matplotlib or Seaborn for visualizations.
EDA reveals crucial insights about data quality, missing values, and potential feature engineering opportunities. This knowledge directly impacts your preprocessing decisions and model selection strategy.
Step 2: Data Preprocessing and Cleaning
Data preprocessing is arguably the most critical phase when you build machine learning models. Raw data rarely comes in perfect, analysis-ready form. Effective data cleaning and preprocessing can dramatically improve model accuracy and performance.
Handling Missing Values
Missing data is common in real-world datasets and must be addressed before model training. Several strategies exist for handling missing values:
Deletion: Remove rows or columns with missing values. This approach works when missing data is minimal and randomly distributed, but it risks losing valuable information.
Imputation: Fill missing values with statistical measures like mean, median, or mode. Scikit-learn’s SimpleImputer class provides efficient imputation methods for both numerical and categorical features.
Advanced Techniques: Use machine learning algorithms to predict missing values based on other features in your dataset.
Feature Scaling and Normalization
Different features often have vastly different scales, which can negatively impact certain machine learning algorithms. Feature scaling ensures all features contribute proportionally to model training.
Standardization: Transforms features to have zero mean and unit variance using StandardScaler from Scikit-learn. This technique works well with algorithms like Support Vector Machines and Linear Regression.
Normalization: Scales features to a fixed range, typically [0, 1], using MinMaxScaler. This approach suits neural networks and algorithms sensitive to feature magnitude.
Encoding Categorical Variables
Machine learning algorithms require numerical input, but datasets often contain categorical data like colors, cities, or product categories. Encoding converts these text values into numerical representations.
Label Encoding: Assigns each unique category an integer. Suitable for ordinal categories with inherent order.
One-Hot Encoding: Creates binary columns for each category. Scikit-learn’s OneHotEncoder handles this transformation efficiently, preventing algorithms from assuming false ordinal relationships.
Feature Engineering
Feature engineering involves creating new features from existing ones to improve model performance. This creative process requires domain knowledge and experimentation. Examples include extracting date components (year, month, day), combining existing features, or creating polynomial features for linear regression problems.
Step 3: Splitting Your Dataset
Properly dividing your data into distinct sets is crucial for building reliable machine learning models and accurately assessing their performance.
Training, Validation, and Test Sets
The standard practice involves splitting your dataset into three subsets:
Training Set: The largest portion (typically 60-80%) is used to train your machine learning model. The model learns patterns from this data.
Validation Set: A separate portion (10-20%) used during hyperparameter tuning and model selection. This data helps you compare different algorithms and configurations without touching your test data.
Test Set: The final portion (10-20%) is reserved exclusively for final model evaluation. This data remains completely unseen during development, providing an unbiased estimate of model performance on new data.
Scikit-learn’s train_test_split function simplifies this process:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Cross-Validation
Cross-validation provides more robust performance estimates, especially with limited data. K-fold cross-validation divides your training data into K subsets, trains the model K times, each time using a different fold as validation, while the remaining folds serve as training data.
This technique reduces variance in performance metrics and helps detect overfitting. Scikit-learn offers convenient cross_val_score and GridSearchCV functions for implementing cross-validation in your machine learning pipeline.
Step 4: Selecting and Training Your Model
Choosing the right algorithm and training your machine learning model represents the core of your machine learning project.
Choosing the Right Algorithm
Algorithm selection depends on your problem type, dataset characteristics, and performance requirements. For beginners building their first machine learning model, consider these popular options:
Linear Regression: Ideal for regression problems with linear relationships between features and target variables. Simple, interpretable, and computationally efficient.
Logistic Regression: Despite its name, this classification algorithm works excellently for binary classification tasks. It provides probability estimates and interpretable coefficients.
Decision Trees: Versatile algorithms suitable for both classification and regression. They’re easy to understand, require minimal data preprocessing, and handle non-linear relationships naturally.
Random Forest: An ensemble method combining multiple Decision Trees to improve accuracy and reduce overfitting. Excellent general-purpose algorithm for various machine learning tasks.
Support Vector Machines: Powerful classification algorithms that work well with high-dimensional data and complex decision boundaries.
Training Your First Model
Training a machine learning model with Scikit-learn is remarkably straightforward. Here’s a typical workflow for building a classification model:
from sklearn.ensemble import RandomForestClassifier
# Initialize the model
model = RandomForestClassifier(n_estimators=100, random_state=42)
# Train the model
model.fit(X_train, y_train)
# Make predictions
predictions = model.predict(X_test)
The fit() method performs the actual training, adjusting the model’s internal parameters based on your training data. The predict() method generates predictions for new data.
Hyperparameter Tuning
Hyperparameters are configuration settings that control the learning process but aren’t learned from data. Tuning these parameters optimizes model performance.
Grid Search: Exhaustively searches through specified parameter combinations. Scikit-learn’s GridSearchCV automates this process with cross-validation.
Random Search: Samples random parameter combinations, often finding good hyperparameters faster than grid search for large parameter spaces. Start with default hyperparameters for your first model, then gradually explore tuning as you gain experience with machine learning.
Step 5: Evaluating Model Performance
Assessing your machine learning model’s effectiveness requires appropriate evaluation metrics and performance measurement techniques.
Classification Metrics
For classification problems, several metrics provide insight into model performance:
Accuracy: The percentage of correct predictions. Simple, but can be misleading with imbalanced datasets.
Precision: The proportion of positive predictions that are actually correct. Important when false positives are costly.
Recall: The proportion of actual positives correctly identified. Critical when missing positive cases have serious consequences.
F1-Score: The harmonic mean of precision and recall, providing a balanced metric for model evaluation.
Confusion Matrix: A table showing true positives, false positives, true negatives, and false negatives, offering comprehensive performance visualization.
Regression Metrics
For regression problems, use these metrics:
Mean Absolute Error (MAE): Average absolute difference between predictions and actual values. Easy to interpret and robust to outliers.
Mean Squared Error (MSE): Average squared difference between predictions and actual values. Penalizes large errors more heavily.
Root Mean Squared Error (RMSE): Square root of MSE, expressed in the same units as your target variable.
R-squared: Proportion of variance in the target variable explained by your model. Ranges from 0 to 1, with higher values indicating a better fit.
Avoiding Common Pitfalls
Overfitting occurs when your model learns noise in the training data rather than generalizable patterns. It performs excellently on training data but poorly on new data. Underfitting happens when your model is too simple to capture underlying patterns.
Monitor both training and validation performance. Significant gaps indicate overfitting, while uniformly poor performance suggests underfitting. Techniques like cross-validation, regularization, and ensemble methods help mitigate these issues.
Step 6: Improving Your Model
Once you’ve trained and evaluated your initial machine learning model, several strategies can enhance its performance and reliability.
Feature Engineering and Selection

Revisit your features with insights gained from initial model training. Create new features that might capture important patterns, and remove redundant or irrelevant features that add noise.
Feature importance analysis reveals which features most influence predictions. Random Forest and Decision Tree algorithms provide built-in feature importance scores. Remove low-importance features to simplify your model and potentially improve generalization.
Ensemble Methods
Ensemble methods combine multiple models to achieve better performance than individual algorithms. These techniques are powerful tools for improving accuracy and robustness.
Bagging: Trains multiple instances of the same algorithm on different subsets of training data, then averages their predictions. Random Forest exemplifies this approach.
Boosting: Sequentially trains models, with each new model focusing on correcting previous models’ errors. Gradient Boosting and XGBoost are popular implementations.
Stacking: Combines predictions from multiple diverse algorithms using another model to make final predictions.
Regularization Techniques
Regularization prevents overfitting by adding penalties for model complexity. L1 regularization (Lasso) encourages sparse models by driving some coefficients to zero, effectively performing feature selection. L2 regularization (Ridge) penalizes large coefficients without eliminating features entirely.
Scikit-learn implements regularization in most algorithms through hyperparameters like alpha or C, which control regularization strength during model training.
Step 7: Deploying Your Machine Learning Model
Building a machine learning model is only half the journey. Deployment transforms your model from an experimental project into a practical tool that delivers value.
Saving Your Model
Scikit-learn models can be saved using Python’s pickle module or joblib for more efficient serialization:
import joblib
joblib.dump(model, 'my_first_model.pkl')
This creates a file containing your trained model, which can be loaded later without retraining.
Creating a Simple API
To make your model accessible to applications, create an API using frameworks like Flask or FastAPI. This allows other systems to send data to your model and receive predictions.
A basic Flask API might look like:
from flask import Flask, request, jsonify
import joblib
app = Flask(__name__)
model = joblib.load('my_first_model.pkl')
@app.route('/predict', methods=['POST'])
def predict():
data = request.get_json()
prediction = model.predict(data)
return jsonify({'prediction': prediction.tolist()})
Monitoring and Maintenance
Deployed machine learning models require ongoing monitoring and maintenance. Model performance can degrade over time due to changing data distributions, a phenomenon called model drift.
Implement logging to track prediction requests, performance metrics, and potential errors. Regularly retrain your model with fresh data to maintain accuracy. Set up alerts for significant performance drops or unusual prediction patterns.
Common Challenges and Solutions
As you build machine learning models, you’ll encounter various challenges. Common obstacles and their solutions accelerate your learning journey.
Insufficient Data
Limited data hampers model training and performance. Solutions include data augmentation techniques, transfer learning using pre-trained models, or collecting additional data from alternative sources.
Imbalanced Datasets
When one class significantly outnumbers others in classification problems, models are biased toward the majority class. Address this through resampling techniques (oversampling minority class or undersampling majority class), using class weights in your algorithm, or employing specialized metrics like F1-score that account for imbalance.
Computational Limitations
Complex models and large datasets demand significant computational resources. Start with simpler algorithms and smaller data samples. Cloud platforms like Google Colab offer free GPU access for resource-intensive machine learning tasks.
Interpretability vs Performance
Complex models like neural networks often achieve superior accuracy but lack interpretability. Simpler algorithms like Logistic Regression and Decision Trees provide transparent decision-making processes. Choose based on your specific requirements—regulated industries often prioritize interpretability, while others might favor pure performance.
Best Practices for Machine Learning Projects
Following established best practices ensures your machine learning projects remain organized, reproducible, and maintainable.
Documentation and Version Control
Document your entire machine learning process, including data sources, preprocessing steps, algorithm choices, hyperparameters, and evaluation metrics. Use version control systems like Git to track code changes and experiment iterations. Jupyter Notebooks excel at combining code, visualizations, and explanatory text, creating self-documenting machine learning workflows.
Reproducibility
Ensure your machine learning experiments are reproducible by setting random seeds, documenting package versions, and maintaining clear data processing pipelines. Future you (and colleagues) will appreciate being able to recreate results.
Ethical Considerations
Machine learning models can perpetuate or amplify biases present in training data. Carefully examine your data for potential biases, test model behavior across different demographic groups, and consider fairness metrics alongside traditional performance measures. Transparency about model limitations, potential biases, and appropriate use cases is crucial for responsible machine learning deployment.
Next Steps in Your Machine Learning Journey
Completing your first machine learning model is just the beginning of an exciting journey into data science and artificial intelligence.
Deepening Your Knowledge
Explore more advanced algorithms like Neural Networks, Gradient Boosting Machines, and deep learning frameworks like TensorFlow and PyTorch. The mathematical foundations behind machine learning algorithms enhance your intuition and problem-solving abilities. Take online courses, participate in Kaggle competitions, and contribute to open-source machine learning projects to gain practical experience and learn from the community.
Specialization Areas
Machine learning encompasses diverse specialization areas. Natural Language Processing focuses on text data and language. Computer Vision deals with image and video analysis. Time series forecasting applies machine learning to temporal data. Explore different domains to discover your interests and strengths.
Building a Portfolio
Document your machine learning projects and share them on platforms like GitHub or personal websites. A strong portfolio demonstrates your skills to potential employers and collaborators, showcasing your ability to build machine learning models and solve real-world problems.
More Read: How to Choose the Right Machine Learning Framework
Conclusion
Building your first machine learning model represents a significant achievement in your journey toward mastering data science and artificial intelligence. This comprehensive guide walked you through every essential step, from fundamental machine learning concepts and setting up your development environment to data preprocessing, algorithm selection, model training, evaluation, and deployment. You’ve learned how to work with Python and Scikit-learn, handle real-world datasets, select appropriate algorithms, tune hyperparameters, and assess model performance using various metrics.
Remember that becoming proficient in machine learning requires continuous practice, experimentation, and learning from both successes and failures. Start with simple problems, gradually tackle more complex challenges, and don’t hesitate to explore advanced techniques as your confidence grows. The skills you’ve gained in building your first machine learning model serve as a foundation for countless applications across industries, empowering you to transform raw data into actionable insights and intelligent systems that solve meaningful problems in the real world.









