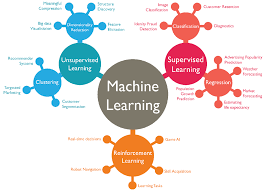
Common Machine Learning Mistakes and How to Fix Them
Discover common machine learning mistakes that derail projects. Learn practical solutions to fix overfitting, data leakage, and model errors

In today’s data-driven landscape, Machine Learning Mistakes has become an indispensable tool for organizations seeking competitive advantages and innovative solutions. From predictive analytics to autonomous systems, machine learning models power countless applications that transform raw data into actionable insights. However, the journey from concept to deployment is fraught with challenges that can compromise even the most promising projects. And avoiding common machine learning mistakes is crucial for data scientists, engineers, and organizations investing significant resources in AI initiatives.
The reality is that machine learning mistakes are surprisingly commonplace, affecting both novice practitioners and experienced professionals. These errors can manifest at any stage of the ML pipeline—from initial data collection and preprocessing to model training, validation, and deployment. The consequences range from minor performance degradation to catastrophic failures that erode stakeholder confidence and waste valuable resources. Research indicates that improper handling of training data, inadequate model validation, and failure to address data quality issues account for the majority of project setbacks.
What makes these pitfalls particularly challenging is that they often remain hidden until models are deployed in production environments, where poor performance becomes immediately apparent. A model that achieves impressive accuracy during training might fail spectacularly when confronted with real-world data, revealing fundamental flaws in the development process. Whether it’s overfitting in machine learning, data leakage, or improper feature selection, each mistake carries specific warning signs and proven remediation strategies.
This comprehensive guide examines the most prevalent machine learning pitfalls that plague modern AI projects and provides actionable solutions to overcome them. We’ll explore critical issues, including data preprocessing errors, model selection mistakes, validation failures, and deployment challenges. By avoiding these common traps and implementing best practices, you can significantly improve your model’s performance, reliability, and real-world applicability. Whether you’re building your first neural network or optimizing an enterprise-scale system, mastering these fundamentals will elevate your machine learning practice and deliver more robust, trustworthy results.
Data-Related Machine Learning Mistakes
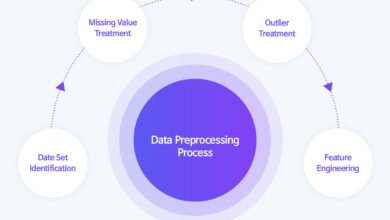
Poor Data Quality and Preprocessing
One of the most fundamental machine learning mistakes involves inadequate attention to data quality. Your model’s performance is ultimately constrained by the quality of data it learns from—a principle often summarized as “garbage in, garbage out.” Noisy data, missing values, inconsistent formatting, and outliers can severely compromise model accuracy and generalization capabilities.
Dirty data manifests in various forms: incomplete records with missing values, categorical features with excessive levels, inconsistent data types across similar fields, and erroneous entries resulting from collection errors. When data contains conflicting or misleading information, even sophisticated algorithms struggle to extract meaningful patterns. Many practitioners rush into model building without thoroughly examining their datasets, only to discover later that fundamental data issues undermined their entire approach.
How to Fix It:
Implement comprehensive data preprocessing workflows that include:
- Systematic missing value analysis using techniques like mean/median imputation, forward-fill methods, or advanced imputation algorithms
- Outlier detection through statistical methods (IQR, Z-scores) and visual inspection
- Data standardization to ensure consistent formatting across all features
- Feature scaling using normalization or standardization to bring variables to comparable ranges
- Rigorous data validation checks before model training begins
Additionally, invest time in exploratory data analysis (EDA) to understand distributions, correlations, and potential anomalies. Creating data quality dashboards and implementing automated validation pipelines can catch issues early in the development cycle.


Data Leakage: The Silent Performance Killer
Data leakage in machine learning represents one of the most insidious and damaging errors that can occur during model development. This mistake happens when information from outside the training dataset inappropriately influences the model, creating artificially inflated performance metrics that don’t translate to real-world scenarios. Data leakage causes models to appear highly accurate during development but fail catastrophically when deployed.
There are two primary forms of leakage: target leakage occurs when features contain information about the target variable that wouldn’t be available at prediction time, while train-test contamination happens when test data inadvertently influences the training process. For example, including future information in predictive models, applying preprocessing transformations before splitting data, or using features derived from the target variable all constitute serious leakage violations.
The danger of data leakage lies in its ability to remain undetected during development. Models with leakage often show suspiciously perfect performance metrics—near 100% accuracy or unrealistically low error rates—that should raise immediate red flags. Unfortunately, these warning signs are sometimes dismissed as indicators of model excellence rather than recognized as symptoms of fundamental flaws.
How to Fix It:
Preventing data leakage requires disciplined workflows:
- Split your dataset into training, validation, and test sets before any preprocessing or feature engineering
- Apply all transformations (scaling, encoding, imputation) independently to each dataset split
- Ensure temporal consistency in time-series problems—never train on future data to predict the past
- Carefully audit features to verify they don’t contain information unavailable at prediction time
- Implement strict separation between training data and evaluation data throughout the pipeline
- Use cross-validation properly, ensuring each fold maintains independence
Regular code reviews focused specifically on potential leakage sources and maintaining clear documentation of feature derivation processes can help teams avoid this critical mistake.
Insufficient or Imbalanced Training Data
The quantity and distribution of training data fundamentally determine model quality. Machine learning algorithms require sufficient examples to learn robust patterns, yet many projects proceed with inadequate datasets. Equally problematic is class imbalance, where certain categories are severely underrepresented, causing models to develop biased predictions favoring majority classes.
When training on imbalanced datasets without proper handling, models often achieve high overall accuracy while performing poorly on minority classes—precisely the categories that frequently represent the most valuable or critical predictions. In fraud detection, medical diagnosis, or rare event prediction, the minority class typically carries the greatest importance.
How to Fix It:
Address data insufficiency and imbalance through multiple strategies:
- Collect additional data when possible, prioritizing underrepresented categories
- Apply data augmentation techniques to synthetically expand limited datasets
- Use resampling methods: oversampling minority classes (SMOTE, ADASYN) or undersampling majority classes
- Implement class-weighted loss functions that penalize misclassification of minority classes more heavily
- Consider ensemble methods that combine multiple models trained on balanced subsets
- Evaluate models using metrics appropriate for imbalanced data: precision, recall, F1-score, and area under the ROC curve, rather than simple accuracy.y
Model Selection and Training Mistakes

Overfitting When Models Memorize Instead of Learn
Overfitting in Machine Learning Mistakes occurs when models become too closely adapted to training data, capturing noise and random fluctuations rather than underlying patterns. An overfitted model performs exceptionally well on training examples but fails to generalize to new, unseen data—the ultimate goal of any machine learning system.
This common mistake typically arises from excessive model complexity relative to available data, insufficient regularization, or prolonged training. Neural networks with too many layers, decision trees with unlimited depth, or models with more parameters than training examples are particularly susceptible. The telltale sign of overfitting is a large gap between training and validation performance: high training accuracy coupled with poor validation accuracy.
How to Fix It:
Combat overfitting through several proven techniques:
- Implement regularization methods (L1/L2 regularization, dropout, early stopping)
- Simplify model architecture by reducing complexity: fewer layers, limited tree depth, or fewer features.
- Increase training data through collection or augmentation
- Use cross-validation to obtain more reliable performance estimates
- Apply ensemble methods that combine multiple models to reduce variance
- Monitor both training and validation metrics throughout development
- Implement early stopping based on validation performance to prevent over-training
Remember that some degree of model complexity is necessary—the goal is finding the optimal balance between underfitting (too simple) and overfitting (too complex).
Underfitting Oversimplification Problems
While less discussed than overfitting, underfitting represents an equally problematic mistake where models are too simplistic to capture the underlying data patterns. An underfitted model performs poorly on both training and test data, indicating insufficient capacity to learn from available information.
Underfitting often results from overly aggressive regularization, inadequate feature engineering, premature stopping of training, or choosing algorithms inappropriate for the problem’s complexity. Linear models applied to highly non-linear relationships or shallow networks attempting to learn complex patterns exemplify this issue.
How to Fix It:
Address underfitting by:
- Increasing model complexity: adding layers to neural networks, increasing tree depth, or incorporating polynomial features
- Reducing the regularization strength if applied too aggressively
- Engineering more informative features that better represent underlying patterns
- Training for additional epochs or iterations
- Selecting more sophisticated algorithms appropriate for problem complexity
- Analyzing learning curves to distinguish between underfitting and overfitting
Improper Hyperparameter Tuning
Hyperparameter tuning significantly impacts model performance, yet many practitioners either neglect this step or approach it ineffectively. Using default hyperparameters, manual trial-and-error without systematic methodology, or tuning on test data rather than validation sets represent common errors that compromise results.
How to Fix It:
Implement systematic hyperparameter optimization:
- Use grid search for exhaustive exploration of predefined parameter ranges
- Apply random search for more efficient exploration of large parameter spaces
- Employ Bayesian optimization for intelligent, adaptive parameter selection
- Leverage automated tools like Optuna, Hyperopt, or AutoML frameworks
- Always tune on validation data, reserving test data for final evaluation
- Document optimal hyperparameters and their selection process
Validation and Evaluation Mistakes
Using Inappropriate Evaluation Metrics
Selecting the wrong evaluation metric is a subtle but consequential Machine Learning Mistakes machine learning mistake. Many projects default to accuracy without considering whether it appropriately measures model success for their specific problem. In imbalanced datasets, high accuracy might mask terrible performance on critical minority classes.
How to Fix It:
Choose metrics aligned with business objectives and data characteristics:
- Classification problems: Consider precision, recall, F1-score, ROC-AUC, and confusion matrices
- Regression problems: Use MAE, RMSE, and R-squared, but understand their different properties
- Imbalanced data: Prioritize precision-recall curves and F1-scores over accuracy
- Business alignment: Define custom metrics reflecting actual costs and benefits
- Multi-metric evaluation: Monitor multiple metrics to gain comprehensive performance
Inadequate Train-Test Split Strategy
Improper data splitting undermines the entire validation process. Common mistakes include using random splits for time-series data, creating splits that break independence assumptions, or using test data multiple times during model selection, which transforms it into validation data.
How to Fix It:
Implement appropriate splitting strategies:
- Time-series data: Use temporal splits respecting chronological order
- Stratified splits: Maintain class distributions across all splits
- K-fold cross-validation: Obtain more robust performance estimates
- Proper test set isolation: Touch test data only once for final evaluation
- Appropriate split ratios: Typically 70-80% training, 10-15% validation, 10-15% testing
Ignoring Model Interpretability and Bias
Deploying black-box models without their decision-making process or checking for model bias can lead to ethical issues, regulatory violations, and user distrust. Models may inadvertently learn discriminatory patterns from biased historical data.
How to Fix It:
Prioritize model interpretability and fairness:
- Use inherently interpretable models (decision trees, linear models) when possible
- Apply post-hoc explanation methods: SHAP values, LIME, or feature importance analysis
- Conduct bias audits examining model predictions across demographic groups
- Implement fairness constraints during training
- Document model limitations and potential biases transparently
- Engage domain experts to validate model logic and decisions
Feature Engineering and Selection Mistakes
Poor Feature Engineering Practices
Feature engineering transforms raw data into representations that Machine Learning Mistakes can effectively learn from. Poor feature engineering—whether through inadequate domain knowledge application, creating irrelevant features, or missing important transformations—severely limits model potential.
How to Fix It:
Develop robust feature engineering processes:
- Collaborate with domain experts to identify meaningful features
- Create interaction terms capturing relationships between variables
- Apply appropriate transformations (logarithmic, polynomial, binning)
- Extract temporal features from timestamps (day of week, seasonality)
- Encode categorical variables appropriately (one-hot, target encoding)
- Normalize or standardize features to comparable scales
Including Irrelevant Features
Adding numerous irrelevant features increases computational costs, training time, and risk of overfitting while potentially degrading model performance through noise introduction. More features don’t always translate to better models.
How to Fix It:
Implement systematic feature selection:
- Use filter methods: correlation analysis, mutual information, statistical tests
- Apply wrapper methods: recursive feature elimination, forward/backward selection
- Leverage embedded methods: L1 regularization (Lasso), tree-based feature importance
- Monitor model performance as features are added or removed
- Balance feature richness with model simplicity
Deployment and Production Mistakes
Neglecting Model Monitoring and Maintenance
Machine Learning Mistakes deployed to production require ongoing monitoring and maintenance. A common mistake is treating deployment as the final step rather than the beginning of a model’s lifecycle. Models degrade over time as data distributions shift, relationships change, and new patterns emerge—a phenomenon called model drift.
How to Fix It:
Establish comprehensive monitoring systems:
- Track prediction distributions and detect significant shifts
- Monitor input feature distributions for data drift
- Implement automated alerts for performance degradation
- Conduct regular model retraining on updated data
- Version models and maintain rollback capabilities
- Document model performance in production environments
Insufficient Testing Before Deployment
Deploying models without adequate testing risks production failures, poor user experiences, and potential harm. Testing only on historical data without considering edge cases, adversarial inputs, or system integration issues leaves critical vulnerabilities unaddressed.
How to Fix It:
Implement thorough pre-deployment testing:
- Conduct A/B testing comparing new models against current production systems
- Test on representative production-like data, including edge cases
- Verify model behavior under various scenarios and data quality conditions
- Assess computational requirements and latency constraints
- Implement gradual rollouts rather than full-scale immediate deployment
- Establish clear rollback procedures for problematic deployments
Ignoring Computational and Scalability Requirements
Developing models without considering production constraints leads to systems that work in development but fail in real-world deployment. Machine Learning Mistakes requiring excessive computational resources, memory, or inference time may be impractical for actual use cases.
How to Fix It:
Consider practical constraints throughout development:
- Define performance requirements early (latency, throughput, resource limits)
- Optimize model architecture for deployment environments
- Apply model compression techniques: quantization, pruning, distillation
- Test models at production scale before deployment
- Balance accuracy with computational efficiency based on business needs
- Consider edge deployment constraints if applicable
Algorithm-Specific Mistakes
Misunderstanding Algorithm Assumptions
Different Machine Learning Mistakes learning algorithms carry specific assumptions about data distributions, feature relationships, and problem structures. Violating these assumptions leads to poor performance and unreliable predictions. For example, linear regression assumes linear relationships and normally distributed errors, while naive Bayes assumes feature independence.
How to Fix It:
Understand and verify algorithm assumptions:
- Study the theoretical foundations of the chosen algorithms
- Test assumptions statistically before model training
- Visualize data to identify violations of linearity, independence, or distribution assumptions
- Transform data when necessary to satisfy requirements
- Select algorithms appropriate for your data characteristics
- Consider ensemble methods combining multiple algorithm types
Wrong Algorithm for the Problem Type
Selecting algorithms mismatched to problem requirements wastes resources and yields suboptimal results. Using classification algorithms for regression problems, applying supervised learning without labeled data, or deploying complex deep learning for simple linear relationships represent common mismatches.
How to Fix It:
Match algorithms to problem characteristics:
- Clearly define the problem type: classification, regression, clustering, dimensionality reduction
- Consider data size: deep learning requires large datasets; traditional algorithms excel with smaller data
- Evaluate interpretability requirements: choose simpler models when explanation is critical
- Assess feature relationships: linear vs. non-linear patterns
- Compare multiple candidate algorithms empirically through systematic experimentation
Collaboration and Documentation Mistakes
Insufficient Documentation and Reproducibility
Machine Learning Mistakes in learning projects without proper documentation become unmaintainable, unreproducible, and difficult to improve. Failing to document data sources, preprocessing steps, hyperparameters, model versions, and experimental results creates technical debt that compounds over time.
How to Fix It:
Establish comprehensive documentation practices:
- Version control all code, data processing scripts, and model configurations
- Document data sources, collection methods, and known limitations
- Record all hyperparameters, training procedures, and experimental results
- Use experiment tracking tools (MLflow, Weights & Biases, Neptune)
- Create reproducible environments using containerization (Docker) or environment files.
- Write clear README files explaining project structure and execution steps
- Maintain model cards documenting intended uses, limitations, and performance characteristics
Poor Communication with Stakeholders
Failing to effectively communicate with non-technical stakeholders about model performance, limitations, and business implications leads to misaligned expectations and poor decision-making. Overpromising model capabilities or using excessive technical jargon alienates stakeholders and undermines project success.
How to Fix It:
Develop effective stakeholder communication:
- Translate technical metrics into business-relevant terms
- Use visualizations to illustrate model behavior and performance
- Clearly communicate model limitations and uncertainty
- Set realistic expectations about what models can and cannot achieve
- Involve stakeholders throughout development to ensure alignment
- Provide regular updates in an accessible language
- Create executive summaries highlighting key findings and recommendations
More Read: Machine Learning Data Preprocessing Best Practices Guide
Conclusion
Avoiding common machine learning mistakes is essential for developing robust, reliable, and effective AI systems that deliver real business value. From data quality issues and data leakage to overfitting, improper validation, and deployment challenges, each mistake carries specific consequences that can derail even well-intentioned projects. Success in machine learning requires disciplined attention to the entire pipeline—from initial data collection and preprocessing through model training, validation, and production deployment.
By implementing systematic approaches to data preprocessing, choosing appropriate algorithms, conducting rigorous validation with proper evaluation metrics, and maintaining deployed models through continuous monitoring, you can dramatically improve your model performance and reliability. Remember that machine learning is an iterative process requiring experimentation, learning from failures, and continuous improvement. The most successful practitioners combine technical expertise with domain knowledge, strong documentation practices, and effective stakeholder communication. As you apply these lessons to your projects, you’ll not only avoid costly machine learning pitfalls but also build more trustworthy, interpretable, and valuable AI systems that solve real-world problems effectively.