Machine Learning Model Deployment From Development to Production
Learn how to deploy machine learning models from development to production. Expert guide covering deployment strategies, MLOps, monitoring

The journey of a machine learning model deployment doesn’t end with achieving impressive accuracy metrics during training. In fact, many organizations discover that building the model represents only half of the challenge—the real test begins when transitioning from development to production environments. Model deployment is the critical process of integrating a trained machine learning model into an existing production system where it can generate real-world predictions and deliver tangible business value. Whether you’re deploying a fraud detection system to monitor live transactions, a recommendation engine to personalize user experiences, or a predictive maintenance model to prevent equipment failures, the intricacies of production deployment are essential for any data scientist or ML engineer in 2025.
The gap between a working prototype and a production-ready system involves numerous technical challenges, from infrastructure setup and API development to monitoring, scaling, and maintaining model performance over time. Modern enterprises demand machine learning models that not only perform accurately but also respond quickly, scale efficiently, and integrate seamlessly with existing applications. This comprehensive guide explores the complete lifecycle of ML model deployment, from initial development considerations through production implementation and ongoing maintenance.
Throughout this article, we’ll examine proven deployment strategies including real-time inference, batch processing, and edge deployment. We’ll delve into MLOps practices that streamline the deployment pipeline, discuss containerization with Docker and Kubernetes, and explore monitoring techniques to ensure your models continue performing optimally in production. Whether you’re deploying your first model or optimizing existing production environments, this guide provides actionable insights to bridge the gap between development and deployment successfully. These concepts are no longer optional—it’s become an essential skill that employers expect from modern data scientists and machine learning practitioners.
Machine Learning Model Deployment
Machine learning deployment refers to the comprehensive process of making a trained ML model available for use in a production environment where it can serve predictions to end-users, applications, or other systems. Unlike traditional software deployment, ML model deployment involves unique challenges related to data dependencies, model versioning, and performance monitoring.
At its core, model deployment transforms an experimental notebook or training script into a robust, scalable service capable of handling real-world traffic. This transformation requires careful consideration of latency requirements, throughput expectations, and reliability standards. Organizations must decide whether to deploy models for real-time inference, where predictions are generated immediately upon request, or batch processing, where predictions are generated for large datasets at scheduled intervals.
The deployment process typically encompasses several critical components: model serialization and packaging, API development for serving predictions, containerization for consistent environments, infrastructure provisioning, and continuous monitoring. Each component plays a vital role in ensuring the deployed model functions reliably and efficiently. Modern deployment strategies also incorporate version control for models, automated testing pipelines, and rollback mechanisms to handle failures gracefully. These fundamentals establish the foundation for successful machine learning model deployment initiatives.
The Machine Learning Lifecycle From Development to Production
The machine learning lifecycle consists of distinct stages that guide models from initial concept through production deployment. This lifecycle begins with problem scoping, where business objectives are translated into machine learning tasks. Following scoping, data collection, and engineering stages involve gathering relevant datasets, cleaning data, and creating features that enable models to learn patterns effectively.
Model training represents the phase where algorithms learn from prepared data, followed by rigorous validation to assess performance using metrics appropriate to the problem domain. However, the lifecycle doesn’t conclude with a trained model—deployment marks the transition where theoretical performance meets practical application. This stage involves integrating the ML model into existing systems, configuring serving infrastructure, and establishing monitoring frameworks.
Post-deployment, continuous monitoring becomes crucial for detecting performance degradation, data drift, or system failures. The lifecycle is inherently iterative; insights from production often reveal opportunities for model improvement, triggering new cycles of data collection, training, and redeployment. Modern MLOps practices automate many lifecycle stages, enabling rapid iteration and reducing the time from development to production. Organizations that master this end-to-end lifecycle gain competitive advantages through faster deployment cycles and more reliable machine learning systems.


Key Challenges in Model Deployment
Deploying machine learning models to production presents numerous technical and organizational challenges that differ significantly from traditional software deployment. One primary challenge involves managing the gap between development and production environments. Models trained on static datasets often encounter data distribution changes in production, a phenomenon known as data drift, which can silently degrade model performance over time.
Infrastructure complexity poses another significant challenge. Production ML systems require robust serving infrastructure capable of handling variable load, maintaining low latency, and scaling automatically. Unlike stateless web services, machine learning models often require substantial computational resources, especially for deep learning architectures. Organizations must balance performance requirements with infrastructure costs while ensuring high availability.
Model versioning and reproducibility create additional complexity. As models evolve through retraining and experimentation, tracking which model version serves production traffic becomes critical. Simultaneously, maintaining reproducibility—ensuring that models can be rebuilt identically from code and data—requires sophisticated version control for datasets, code, and trained model artifacts. Security concerns, including protecting sensitive training data and preventing adversarial attacks, add another layer of complexity. Additionally, integrating ML predictions with existing business logic, handling edge cases gracefully, and establishing clear ownership between data science and engineering teams requires careful coordination and well-defined processes.
Model Deployment Strategies
Real-Time Deployment
Real-time deployment integrates trained models into production environments capable of generating immediate predictions as new data arrives. This deployment strategy is essential for applications requiring instant responses, such as fraud detection systems that evaluate transactions in milliseconds, recommendation engines that personalize content dynamically, or chatbots that generate conversational responses in real-time. Real-time inference demands low-latency serving infrastructure, often implemented through REST APIs or gRPC endpoints that receive requests, execute model predictions, and return results within strict time constraints.
Implementing real-time deployment requires careful optimization of model serving infrastructure. Techniques such as model quantization, which reduces model size and computational requirements, and batching multiple requests together can significantly improve throughput. Containerization technologies like Docker enable consistent deployment across environments, while orchestration platforms like Kubernetes facilitate automatic scaling based on traffic patterns. Monitoring becomes particularly critical in real-time systems, where degraded performance directly impacts user experience. Organizations must implement comprehensive logging, latency tracking, and automated alerts to detect issues promptly.
Batch Deployment
Batch deployment processes large volumes of data at scheduled intervals rather than responding to individual requests immediately. This approach suits scenarios where immediate predictions aren’t necessary, such as generating daily customer churn scores, processing overnight data pipelines, or creating periodic sales forecasts. Batch processing allows organizations to optimize resource utilization by running predictions during off-peak hours and leveraging more cost-effective computational resources.
The batch deployment workflow typically involves extracting data from databases or data lakes, preprocessing it according to model requirements, generating predictions for all records, and storing results in databases or data warehouses for downstream consumption. While batch systems tolerate higher latency than real-time deployments, they still require robust orchestration to handle failures, retry mechanisms, and data quality checks. Modern data pipeline tools like Apache Airflow or Prefect orchestrate these workflows, ensuring reliable execution and providing visibility into pipeline health.
Edge Deployment
Edge deployment positions machine learning models on devices at the network edge—smartphones, IoT sensors, embedded systems—rather than centralized servers. This deployment strategy offers significant advantages, including reduced latency by eliminating network round-trips, improved privacy by processing sensitive data locally, and continued functionality during network disruptions. Applications like mobile computer vision, autonomous vehicles, and smart home devices increasingly rely on edge deployment to deliver responsive, privacy-preserving experiences.
However, edge deployment introduces unique challenges. Models must be optimized aggressively to run on resource-constrained devices with limited memory, processing power, and battery life. Frameworks like TensorFlow Lite, ONNX Runtime, and PyTorch Mobile enable the deployment of optimized models on edge devices. Organizations must also address model update mechanisms, ensuring deployed models can be updated remotely while managing bandwidth constraints and version consistency across distributed device fleets.
MLOps Bridging Development and Production
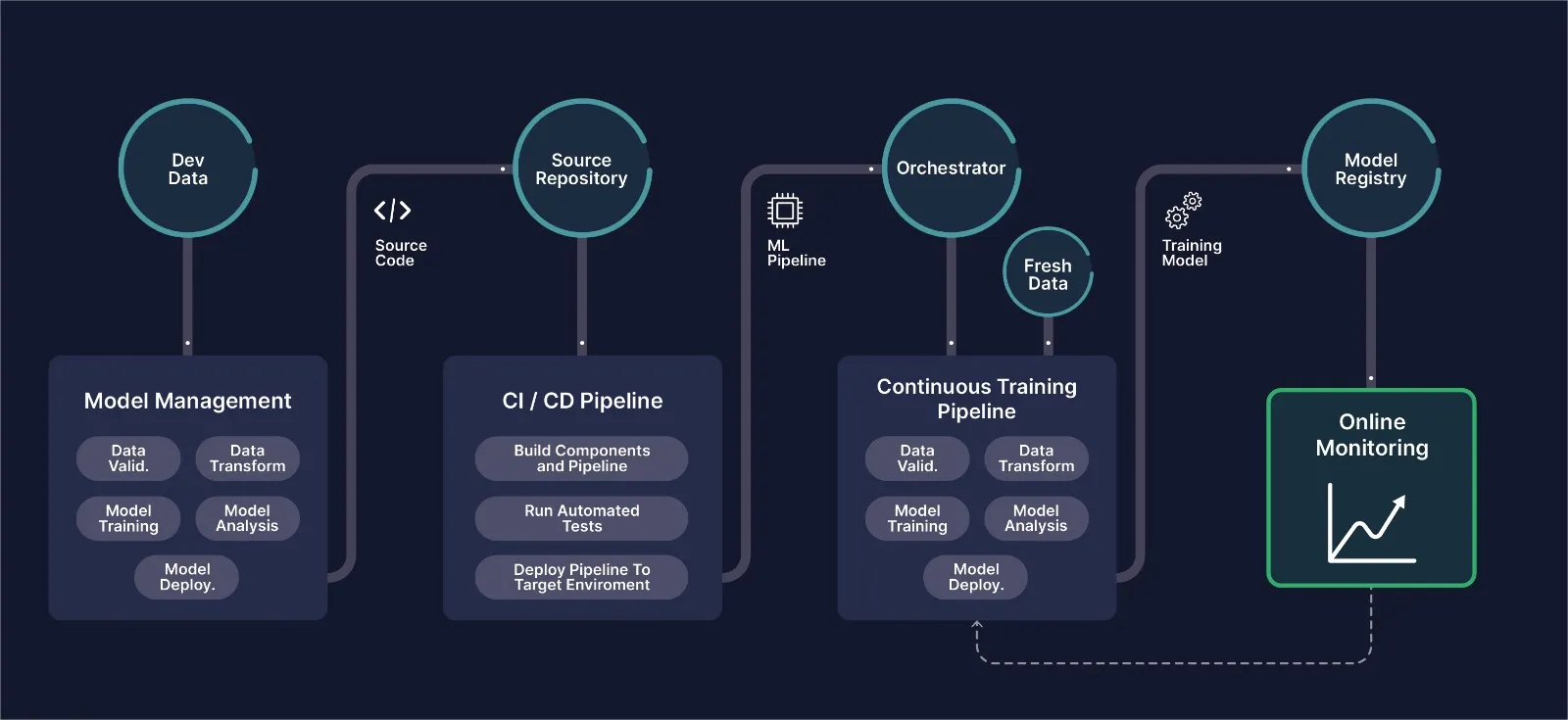
MLOps—machine learning operations—represents the set of practices, processes, and tools that streamline the deployment and management of machine learning models in production. Drawing inspiration from DevOps principles, MLOps addresses the unique challenges of ML systems, including data dependencies, model versioning, and continuous retraining. By implementing MLOps practices, organizations accelerate deployment cycles, improve model reliability, and establish reproducible workflows from experimentation through production.
Core MLOps principles include continuous integration and continuous deployment (CI/CD) adapted for machine learning. CI/CD pipelines automatically test code changes, validate data quality, and assess model performance before deployment. Continuous training extends these concepts further, automatically retraining models when new data becomes available or performance degrades. Comprehensive monitoring and observability enable teams to detect issues quickly, while automated rollback mechanisms provide safety nets when deployments encounter problems.
MLOps platforms and tools have emerged to support these practices. Version control systems like Git manage code, while specialized tools like DVC (Data Version Control) handle dataset versioning. Experiment tracking platforms such as MLflow and Weights & Biases record model performance across countless iterations. Model registries provide centralized repositories for trained models, complete with metadata, performance metrics, and lineage information. Infrastructure as code tools enable reproducible environment provisioning, while orchestration platforms coordinate complex workflows spanning data preparation, training, and deployment. Successful MLOps implementation requires cultural changes alongside technical tools, fostering collaboration between data scientists, ML engineers, and operations teams.
Containerization and Orchestration for ML Models
Containerization has become fundamental to modern machine learning deployment, providing consistent, reproducible environments that eliminate “works on my machine” problems. Docker, the dominant containerization technology, packages ML models along with their dependencies—Python libraries, system packages, and configuration files—into portable containers that run identically across development, testing, and production environments. This consistency dramatically reduces deployment friction and enables reliable model serving.
Creating effective Docker containers for machine learning models requires careful attention to image size, security, and optimization. Base images should be carefully selected—minimal images reduce attack surfaces and improve startup times. Multi-stage builds separate model training artifacts from serving infrastructure, keeping production images lean. Environment variables and configuration files enable flexible deployment across different environments without rebuilding containers. Security best practices include running containers with non-root users, scanning images for vulnerabilities, and keeping dependencies updated.
Kubernetes extends containerization benefits by orchestrating containers at scale. Kubernetes automates the deployment, scaling, and management of containerized applications, making it ideal for production ML systems. It provides horizontal pod autoscaling, automatically adjusting the number of model serving instances based on CPU utilization or custom metrics like request queue length. Load balancing distributes traffic across instances, while rolling updates enable zero-downtime deployments of new model versions. Service meshes like Istio add advanced traffic management capabilities, including canary deployments, A/B testing, and circuit breaking. For organizations running multiple ML models, Kubernetes provides a unified infrastructure for managing diverse serving requirements efficiently.
Model Serving Architecture and APIs
An effective model serving architecture forms the backbone of successful production ML systems. At the center of most architectures sits a prediction API that receives input data, preprocesses it according to model requirements, invokes the machine learning model for inference, and returns predictions in a standardized format. REST APIs using frameworks like Flask or FastAPI offer simplicity and broad compatibility, while gRPC provides superior performance for high-throughput scenarios through efficient binary serialization and HTTP/2 multiplexing.
Designing robust APIs requires careful consideration of input validation, error handling, and response formatting. Input validation ensures only well-formed requests reach the model, preventing errors and potential security issues. Comprehensive error handling provides meaningful error messages while logging failures for debugging. Response schemas should be well-documented, versioned, and include confidence scores or uncertainty estimates alongside predictions. Authentication and authorization mechanisms protect APIs from unauthorized access, particularly important when serving models that process sensitive data or consume expensive computational resources.
Specialized model serving frameworks simplify deployment while providing production-grade features. TensorFlow Serving optimizes serving for TensorFlow models, offering features like model versioning, batching, and GPU acceleration out of the box. TorchServe provides similar capabilities for PyTorch models, while framework-agnostic solutions like Seldon Core and KFServing (now KServe) support models from multiple frameworks within a unified infrastructure. These frameworks handle concerns like multi-model serving, dynamic batching to improve throughput, model warming to reduce cold-start latency, and comprehensive metrics collection. Choosing appropriate serving infrastructure depends on performance requirements, framework preferences, and operational complexity tolerance.
Monitoring and Maintaining Production Models
Monitoring deployed models is essential for maintaining reliable production ML systems. Unlike traditional software, where functionality either works or fails clearly, machine learning models can degrade silently as data distributions shift, producing plausible but increasingly inaccurate predictions. Comprehensive monitoring encompasses multiple dimensions: system health metrics like latency, throughput, and error rates; model performance metrics including accuracy, precision, recall, and domain-specific measures; and data quality metrics that detect distribution shifts.
Implementing effective monitoring requires establishing baseline performance metrics during initial deployment and continuously comparing production behavior against these baselines. Automated alerts trigger when metrics deviate significantly, enabling rapid response to issues. Observability platforms aggregate metrics, logs, and traces, providing comprehensive visibility into model serving systems. Feature drift detection compares statistical properties of production input data against training distributions, identifying when retraining might be necessary. Prediction drift monitoring tracks changes in model output distributions, potentially indicating shifts in underlying data or model degradation.
Model maintenance extends beyond monitoring to encompass active interventions that preserve model quality. Regular retraining cycles incorporate new data, helping models adapt to evolving patterns. A/B testing compares new model versions against existing ones in production, validating improvements before full rollout. Shadow mode deployment runs new models alongside production systems without serving results to users, building confidence before promotion. Model debugging tools help diagnose performance issues, whether they stem from data quality problems, concept drift, or model limitations. Organizations should establish clear processes for model retirement, deprecating underperforming models while maintaining compatibility for dependent systems.
Security and Compliance in Model Deployment

Security considerations in machine learning deployment span model protection, data privacy, and infrastructure security. Model theft poses a real threat—adversaries might extract model parameters through prediction APIs or replicate model behavior through black-box attacks. Defensive measures include rate limiting to prevent extensive probing, input perturbation that adds noise without significantly impacting predictions, and monitoring for suspicious query patterns. Watermarking techniques embed identifiable signatures within models, enabling detection if stolen models surface.
Data privacy becomes paramount when deploying models that process sensitive information. Differential privacy techniques add carefully calibrated noise during training, providing mathematical guarantees about individual data point privacy. Federated learning enables model training across distributed datasets without centralizing sensitive data, particularly valuable in healthcare and financial applications. Encryption mechanisms protect data in transit and at rest, while access controls ensure only authorized systems and users interact with ML APIs. Organizations must navigate complex regulatory landscapes, including GDPR, HIPAA, and industry-specific requirements, implementing audit trails and data retention policies accordingly.
Infrastructure security follows standard security best practices but requires additional considerations for ML systems. Container scanning identifies vulnerabilities in base images and dependencies. Network policies restrict communication between services according to least-privilege principles. Secrets management systems like HashiCorp Vault securely store API keys, database credentials, and other sensitive configurations. Regular security audits assess deployed systems against evolving threat landscapes. For highly sensitive applications, techniques like homomorphic encryption enable computation on encrypted data, preventing exposure even during processing. Balancing security requirements with performance and operational simplicity requires careful consideration of threat models and organizational risk tolerance.
Best Practices for Successful Model Deployment
Successful machine learning model deployment requires adopting proven practices that minimize risks while accelerating time-to-production. Start by establishing clear deployment criteria—quantitative thresholds for accuracy, latency, and resource consumption that models must meet before production promotion. Document model assumptions, limitations, and expected input formats comprehensively, creating a shared understanding between data science and engineering teams. Implement gradual rollouts rather than instantaneous switches, using techniques like canary deployments that initially route small traffic percentages to new models while monitoring for issues.
Version control everything—not just code, but also data, models, and configuration files. Git manages code effectively, while tools like DVC track datasets and model artifacts. Model registries provide centralized storage for trained models along with performance metrics, training parameters, and deployment history. This comprehensive versioning enables reproducibility and facilitates rollback when problems arise. Automate testing throughout the pipeline, validating data quality, checking for feature distribution shifts, and assessing model performance on held-out datasets before deployment.
Foster cross-functional collaboration between data scientists who develop models, ML engineers who deploy them, and platform engineers who maintain infrastructure. Establish clear handoff processes, shared ownership of production systems, and blameless postmortems when issues occur. Invest in observability early—instrumentation added after problems emerge proves far more difficult. Design for failure by implementing circuit breakers, timeouts, and fallback mechanisms that gracefully handle model serving errors. Continuously iterate based on production learnings, treating deployment not as a one-time event but as an ongoing process of refinement and improvement.
Tools and Platforms for Model Deployment
The ML deployment ecosystem offers numerous tools addressing different aspects of the production lifecycle. Cloud platforms provide comprehensive managed services—AWS SageMaker, Google Cloud AI Platform, and Azure Machine Learning offer end-to-end capabilities from experimentation through deployment and monitoring. These platforms simplify infrastructure management while providing enterprise-grade features like automatic scaling, model versioning, and integrated monitoring. However, cloud solutions introduce vendor lock-in considerations and ongoing costs that scale with usage.
Open-source alternatives provide flexibility and control at the cost of increased operational complexity. MLflow offers experiment tracking, model packaging, and a model registry, establishing standardized workflows across frameworks. Kubeflow builds atop Kubernetes, providing ML-specific abstractions for training and serving. Ray Serve enables scalable model serving with sophisticated request routing and batching. BentoML simplifies model deployment by generating containerized prediction services from trained models. These tools can be deployed on-premises or in cloud environments, offering flexibility while requiring more infrastructure expertise.
Specialized deployment platforms target specific deployment patterns. TensorFlow Serving and TorchServe optimize serving for their respective frameworks, providing features like multi-model serving and GPU acceleration. Seldon Core and KServe enable advanced deployment patterns, including multi-armed bandits, explainability integration, and outlier detection. MLOps platforms like Weights & Biases, Neptune, and Comet provide comprehensive experiment tracking and collaboration features. Selecting appropriate tools depends on organizational constraints, including existing infrastructure, team expertise, budget, and specific deployment requirements. Many organizations adopt hybrid approaches, combining multiple tools to address different aspects of the ML lifecycle.
Future Trends in Machine Learning Deployment
Machine learning deployment continues evolving rapidly, with emerging trends reshaping how organizations build and operate production ML systems. AutoML and automated deployment pipelines promise to democratize ML deployment, reducing specialized expertise requirements through intelligent automation. These systems automatically select appropriate deployment strategies, configure infrastructure, and establish monitoring based on model characteristics and business requirements. Low-code and no-code platforms extend this accessibility further, enabling business analysts and domain experts to deploy models without extensive programming knowledge.
Edge AI deployment is accelerating, driven by 5G networks, improved mobile processors, and growing privacy concerns. Techniques like model compression, quantization, and neural architecture search optimize models for resource-constrained devices without significant accuracy loss. Federated learning enables collaborative model training across distributed edge devices while preserving data privacy, opening new possibilities for applications handling sensitive data. Real-time model updates to edge deployments improve, with differential updates reducing bandwidth requirements and enabling rapid response to emerging patterns.
Explainable AI (XAI) integration into deployment pipelines addresses growing regulatory and ethical requirements for model transparency. Production systems increasingly incorporate explanation generation alongside predictions, enabling stakeholders to understand and trust model decisions. AI governance frameworks standardize processes for model validation, bias detection, and compliance documentation. Continuous learning systems blur boundaries between training and serving, updating models incrementally as new data arrives rather than relying on periodic batch retraining. These trends collectively point toward more automated, accessible, and responsible machine learning deployment practices that align technical capabilities with business needs and societal expectations.
More Read: Common Machine Learning Mistakes and How to Fix Them
Conclusion
Machine learning model deployment represents a critical bridge between experimental data science and business value creation. Successfully transitioning models from development to production requires deployment strategies, implementing MLOps practices, establishing robust monitoring, and addressing security considerations. Organizations that master the deployment lifecycle—from initial model training through production serving and ongoing maintenance—gain significant competitive advantages through faster iteration cycles and more reliable ML systems.
As the field continues evolving with emerging tools and techniques, the fundamental principles remain constant: prioritize reproducibility, automate repetitive tasks, monitor comprehensively, and foster collaboration between data science and engineering teams. Whether deploying your first model or optimizing existing production environments, treating deployment as an integral part of the machine learning lifecycle rather than an afterthought ensures models deliver sustained business impact long after initial development concludes.