The success of any artificial intelligence system fundamentally depends on the quality and relevance of its training data. As organizations worldwide accelerate their AI adoption, the demand for well-structured, accurately labeled, and ethically sourced datasets has reached unprecedented levels. Machine learning models are only as effective as the data they learn from, making data collection, preparation, and quality assurance the cornerstone of successful AI implementation.
In today’s competitive landscape, businesses that invest in AI training data infrastructure gain significant advantages in model performance, deployment speed, and operational efficiency. Whether developing computer vision systems for autonomous vehicles, natural language processing applications for customer service, or predictive analytics for healthcare, the pathway to success begins with robust data management practices. The challenge lies not merely in accumulating vast quantities of information, but in ensuring that every data point contributes meaningful insights to the learning process.
The evolution of AI and machine learning technologies has transformed how organizations approach data preparation. Modern AI systems require diverse, representative datasets that capture real-world complexity while maintaining consistency and accuracy. This necessitates sophisticated data collection strategies, rigorous annotation processes, and comprehensive quality control mechanisms. From initial data acquisition through final validation, each stage demands careful attention to detail and adherence to best practices.
Furthermore, the importance of data quality extends beyond technical considerations to encompass ethical responsibilities. Bias in training data can perpetuate discrimination, while inadequate privacy protections can compromise user trust. Organizations must therefore implement holistic approaches that balance technical excellence with ethical accountability. This comprehensive guide explores the essential methodologies, tools, and strategies for effective AI training data management, providing actionable insights for data scientists, machine learning engineers, and AI practitioners seeking to build reliable, high-performing models that deliver transformative business value in an increasingly data-driven world.
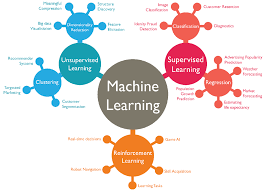
AI Training Data Fundamentals
AI training data serves as the educational foundation upon which machine learning algorithms build their predictive capabilities. At its core, training data consists of examples that teach AI models to recognize patterns, make decisions, and generate outputs. This dataset includes input features paired with corresponding outputs or labels, enabling supervised learning models to establish correlations between variables. The quality, diversity, and volume of this training dataset directly influence the model’s accuracy, generalization ability, and real-world performance.
Different AI applications require distinct types of training data. Computer vision projects demand extensive image and video datasets with precise annotations identifying objects, boundaries, and classifications. Natural language processing models need text corpora representing diverse linguistic patterns, contexts, and semantic relationships. Speech recognition systems require audio files paired with accurate transcriptions, while recommendation engines leverage user behavior data to predict preferences. These specific requirements enable organizations to design targeted data collection strategies aligned with their AI objectives.
The concept of ground truth is fundamental to training data quality. Ground truth represents the correct answer or ideal output for each training example, serving as the benchmark against which the model measures its predictions. Establishing accurate ground truth labels through expert annotation ensures models learn correct patterns rather than perpetuating errors. This is particularly critical in high-stakes applications like medical diagnosis or financial fraud detection, where inaccurate training data can lead to costly mistakes or harmful outcomes.
Data Collection Strategies and Methodologies
Effective data collection begins with clearly defined objectives and success metrics. Organizations must identify what specific problems their AI models will solve, what types of data will provide relevant insights, and what volume of information is necessary for robust training. This strategic planning phase prevents wasteful collection of irrelevant data while ensuring comprehensive coverage of edge cases and diverse scenarios that the model will encounter in production environments.
Primary data collection involves gathering original information directly from source systems, sensors, or user interactions. This approach provides fresh, relevant data tailored to specific use cases but requires significant time and resource investment. Methods include surveys, experiments, sensor deployments, web scraping, and transaction logging. For instance, autonomous vehicle companies collect millions of miles of driving data through equipped vehicles, while chatbot developers record actual customer conversations to build realistic training datasets for conversational AI.


Secondary data collection leverages existing datasets from public repositories, commercial data providers, or partner organizations. Resources like ImageNet, COCO, WikiText, and domain-specific databases offer pre-collected data that accelerates development timelines. However, data scientists must carefully evaluate these sources for relevance, quality, licensing restrictions, and potential biases. Combining primary and secondary sources often yields optimal results, providing both breadth through existing datasets and specificity through custom collection efforts.
Synthetic data generation has emerged as a powerful complement to traditional collection methods. Using simulation tools, generative models, or procedural algorithms, organizations can create artificial training examples that augment real-world data. This approach proves particularly valuable for rare events, dangerous scenarios, or privacy-sensitive situations where collecting actual data is impractical or unethical. However, synthetic data must be carefully validated to ensure it accurately represents real-world distributions and doesn’t introduce artificial biases that compromise model performance.
Data Preparation and Preprocessing Techniques

Data preparation transforms raw information into clean, structured formats suitable for machine learning training. This critical phase typically consumes 60-80% of a data science project’s timeline, yet directly impacts model performance and reliability. The preprocessing pipeline includes cleaning, transformation, normalization, and feature engineering steps that convert messy, inconsistent source data into coherent training examples.
Data cleaning addresses quality issues, including missing values, duplicates, outliers, and inconsistencies. Missing data can be handled through deletion, imputation using statistical methods, or forward-filling from previous values. Duplicate records must be identified and removed to prevent the model from overweighting certain examples. Outliers require careful analysis—some represent valuable edge cases while others indicate measurement errors or data corruption. Robust data cleaning processes employ automated validation rules combined with manual review of flagged issues.
Data transformation converts information into formats optimized for machine learning algorithms. Categorical variables are encoded numerically through one-hot encoding, label encoding, or embedding techniques. Text data undergoes tokenization, stemming, and vectorization to create numerical representations. Images are resized, normalized, and augmented through rotations, flips, or color adjustments. Time series data may be resampled, smoothed, or decomposed into trend and seasonal components. These transformations ensure algorithms can effectively process diverse data types.
Feature engineering creates new variables that better capture patterns relevant to the prediction task. Domain expertise guides the creation of derived features, interaction terms, and aggregated metrics that enhance the model. For example, in credit risk modeling, raw transaction data can be transformed into features like average monthly spending, transaction frequency patterns, and payment history ratios. Effective feature engineering often provides greater performance improvements than algorithm selection, making it a critical data preparation skill.
Data normalization and scaling ensure features contribute proportionally to model training. Standardization converts features to have zero mean and unit variance, while min-max scaling transforms values to a fixed range like [0,1]. These techniques prevent features with larger numeric ranges from dominating the learning process. Proper scaling is essential for algorithms like neural networks and support vector machines that are sensitive to feature magnitudes.
Data Annotation and Labeling Processes
Data annotation is the process of adding meaningful labels or metadata to raw data, creating the supervised learning examples that enable AI models to learn patterns. This labor-intensive process requires human annotators with domain expertise to examine each data point and assign appropriate labels according to predefined guidelines. The accuracy and consistency of data labeling directly determine model performance, making annotation quality a top priority for AI training data initiatives.
Different annotation types serve various machine learning applications. Image annotation includes bounding boxes for object detection, polygonal segmentation for precise boundaries, key point labeling for pose estimation, and semantic segmentation assigning class labels to every pixel. Text annotation encompasses sentiment classification, named entity recognition, relationship extraction, and intent labeling. Audio annotation identifies speakers, transcribes speech, and labels acoustic events. Each annotation type requires specialized tools and trained annotators familiar with task-specific requirements.
Annotation tools streamline the labeling process through intuitive interfaces and automation features. Platforms like Label Studio, Labelbox, and Amazon SageMaker Ground Truth provide collaborative environments where annotation teams can efficiently process large datasets. Advanced tools incorporate machine learning assistance, using model predictions to pre-label data that annotators then verify and correct. This human-in-the-loop approach accelerates annotation while maintaining quality, as models improve iteratively from validated examples.
Annotation guidelines establish clear, consistent standards for labeling decisions. Comprehensive guidelines include definitions for each label class, decision trees for ambiguous cases, visual examples of correct annotations, and procedures for handling edge cases. Well-documented guidelines reduce annotator disagreement and ensure consistency across large teams working on extended projects. Regular guideline updates incorporate lessons learned during annotation, refining standards based on actual challenges encountered.
Inter-annotator agreement metrics measure consistency between different annotators labeling the same data. Cohen’s kappa, Fleiss’ kappa, and percentage agreement quantify how reliably annotators produce identical labels. Low agreement indicates unclear guidelines, insufficient training, or inherently ambiguous data requiring expert review. Many projects employ multiple annotators per example, using majority voting or expert adjudication to resolve disagreements and establish authoritative ground truth labels.
Quality Assurance and Validation Methods
Quality assurance for AI training data encompasses systematic processes to identify and correct errors, inconsistencies, and biases that compromise model performance. Robust QA practices combine automated validation checks, statistical analysis, and human review to ensure datasets meet defined quality standards before training begins. Organizations investing in comprehensive quality control reduce costly model retraining cycles and accelerate deployment timelines.
Automated validation employs programmatic checks to detect common data quality issues. Schema validation verifies that data conforms to expected formats, types, and value ranges. Consistency checks identify logical contradictions, such as end dates preceding start dates or mutually exclusive labels appearing together. Completeness checks flag missing required fields or sparse features with excessive null values. Duplicate detection identifies identical or near-identical records that could skew training. These automated checks provide rapid, scalable quality assessment across massive datasets.
Statistical quality assessment analyzes data distributions to identify anomalies, imbalances, and drift. Class distribution analysis reveals whether label categories are appropriately balanced or if minority classes require augmentation. Feature distribution analysis identifies unusual skewness, unexpected outliers, or shifts from expected patterns. Correlation analysis detects multicollinearity between features or suspicious relationships between inputs and labels. Statistical profiling provides quantitative evidence of data quality and guides targeted improvement efforts.
Human quality review provides a nuanced evaluation that automated methods cannot replicate. Subject matter experts sample data subsets, verifying annotation accuracy against their domain knowledge. Reviewers assess whether labels capture intended semantic meaning, whether guidelines are being consistently applied, and whether edge cases are handled appropriately. This qualitative assessment identifies subtle quality issues like contextual misunderstandings or systematic annotator errors that statistical methods might miss.
Bias detection and mitigation ensure training data represent diverse populations and scenarios without perpetuating discriminatory patterns. Demographic analysis examines representation across protected characteristics like race, gender, and age. Performance disparity testing evaluates whether model accuracy varies significantly across subgroups. Fairness metrics like demographic parity and equalized odds quantify bias in predictions. When biases are detected, mitigation strategies include targeted data collection for underrepresented groups, resampling techniques, or algorithmic fairness constraints during training.
Continuous monitoring extends quality assurance beyond initial dataset creation. As models deploy and generate predictions on real data, monitoring systems track prediction distributions, error patterns, and performance metrics. Significant deviations from expected behavior trigger investigations into potential data drift, where production data characteristics diverge from training data distributions. Regular quality audits and dataset refreshes maintain model relevance as real-world conditions evolve.
Best Practices for Managing Training Data Lifecycles
Effective training data management requires systematic approaches spanning the entire data lifecycle from collection through retirement. Establishing clear governance frameworks, standardized processes, and appropriate tooling ensures data quality, accessibility, and compliance throughout AI development and deployment. Organizations with mature data management practices achieve faster model iterations, better reproducibility, and reduced operational risks.
Data versioning tracks changes to datasets over time, enabling reproducibility and rollback capabilities. Version control systems purpose-built for data, like DVC (Data Version Control) or Delta Lake, manage large binary files and metadata more effectively than traditional code versioning tools. Each dataset version receives unique identifiers, creation timestamps, and change logs documenting what was modified and why. This traceability proves essential when debugging model performance issues or auditing compliance with regulatory requirements.
Metadata management enriches raw data with contextual information that aids discovery and appropriate usage. Comprehensive metadata includes data provenance (source and collection methods), quality metrics, statistical summaries, annotation guidelines, licensing restrictions, and known limitations. Well-documented metadata enables data scientists to quickly assess dataset suitability for new projects, understand preprocessing requirements, and avoid inappropriate applications that could yield unreliable results.
Data cataloging creates searchable inventories of available datasets across organizations. Centralized data catalogs with intuitive search interfaces help teams discover existing resources before initiating costly new data collection efforts. Tagging datasets with descriptive keywords, use cases, and quality ratings facilitates discovery. Access controls within catalogs ensure sensitive data remains restricted to authorized users while maximizing the availability of non-sensitive resources.
Storage optimization balances accessibility with cost-efficiency for large-scale training datasets. Hot storage provides rapid access for active development, while warm storage offers economical options for less frequently accessed historical data. Cold storage archives retired datasets at minimal cost but with slower retrieval times. Automated tiering policies migrate data between storage classes based on access patterns, optimizing costs without compromising availability when needed.
Data security and privacy protections safeguard sensitive information throughout the lifecycle. Encryption at rest and in transit prevents unauthorized access. Access controls implement least-privilege principles, granting permissions only as required for specific roles. Anonymization and differential privacy techniques protect individual privacy in datasets containing personal information. Regular security audits and compliance assessments ensure controls remain effective as threats evolve.
Tools and Technologies for AI Training Data
The AI training data ecosystem encompasses diverse tools supporting collection, annotation, quality assurance, and management activities. Selecting appropriate technologies requires specific project needs, team capabilities, integration requirements, and budget constraints. Leading organizations often combine multiple specialized tools into comprehensive pipelines optimized for their unique workflows.
Data collection platforms automate gathering information from various sources. Web scraping tools like Scrapy and BeautifulSoup extract data from websites. API integration platforms connect to external data providers. IoT data platforms aggregate sensor streams from connected devices. Survey platforms like Qualtrics collect structured feedback. ETL (Extract, Transform, Load) tools like Apache Airflow orchestrate complex collection workflows across multiple sources.
Annotation platforms provide collaborative environments for efficient data labeling. Enterprise solutions like Scale AI, Labelbox, and Appen offer managed services with trained annotator workforces. Open-source alternatives like Label Studio and CVAT provide self-hosted flexibility. Cloud provider offerings, including Amazon SageMaker, Ground Truth, and Google Vertex AI, integrate annotation directly with model training workflows. Platform selection depends on data sensitivity, budget, required annotation types, and desired level of automation.
Quality assurance tools automate validation and monitoring processes. Data quality platforms like Great Expectations define testable expectations for datasets and generate quality reports. Statistical analysis libraries in Python (pandas, numpy, scipy) enable custom quality assessments. Visualization tools like Tableau and Plotly help analysts explore data distributions and identify anomalies. Bias detection libraries like Fairlearn and AI Fairness 360 quantify and mitigate algorithmic bias.
Data management platforms provide end-to-end infrastructure for training data lifecycles. MLOps platforms like MLflow and Weights & Biases track experiments, datasets, and models with full lineage. Feature stores like Feast and Tecton centralize feature engineering and serve features consistently across training and production. Data versioning systems like DVC integrate with existing storage and enable reproducible pipelines. Data catalogs like Apache Atlas and Amundsen provide searchable inventories with rich metadata.
Cloud infrastructure offers scalable storage and compute for data-intensive AI projects. Object storage services (AWS S3, Google Cloud Storage, Azure Blob Storage) provide cost-effective persistence for large datasets. Managed databases support structured data with robust query capabilities. Distributed computing frameworks like Apache Spark process massive datasets across clusters. GPU-accelerated instances enable efficient annotation tool rendering and data augmentation operations.
Emerging Trends and Future Directions
The AI training data landscape continues evolving rapidly, driven by advances in machine learning techniques, growing data volumes, and increasing emphasis on responsible AI. Emerging trends help organizations prepare for future requirements and capitalize on new capabilities that improve efficiency, quality, and ethical outcomes.
Synthetic data generation is maturing from an experimental technique to a mainstream practice. Advanced generative models create increasingly realistic synthetic examples that augment or replace real-world data. Synthetic data addresses privacy concerns, enables rare scenario modeling, and reduces collection costs. Industries with strict privacy regulations, like healthcare and finance, are pioneering synthetic data adoption, with tools like Mostly AI and Gretel.ai leading the market.
Active learning optimizes annotation efficiency by intelligently selecting which examples to label. Rather than randomly sampling data for annotation, active learning algorithms identify examples where labels would most improve model performance. This approach can reduce annotation requirements by 50-90% while maintaining model quality, making it particularly valuable for projects with limited labeling budgets or expensive domain expert time.
Self-supervised learning reduces dependency on labeled data by training models to predict parts of inputs from other parts. Techniques like masked language modeling (used in BERT) and contrastive learning (used in vision models) enable models to learn rich representations from unlabeled data. While these approaches don’t eliminate labeling needs, they dramatically reduce the volume of annotated examples required for downstream tasks.
Federated learning trains models across decentralized datasets without centralizing sensitive information. Participating organizations keep data on-premises while contributing to shared model development. This approach enables collaboration on sensitive data like medical records or financial transactions while preserving privacy and meeting regulatory requirements. Federated learning infrastructure is becoming increasingly accessible through frameworks like TensorFlow Federated.
Data-centric AI shifts focus from model architectures to systematic data quality improvement. This movement, championed by AI pioneers like Andrew Ng, emphasizes that consistent, high-quality data often yields greater performance gains than algorithmic innovations. Data-centric practices include rigorous error analysis, targeted data collection for model weaknesses, and iterative label refinement based on model failures.
Automated machine learning (AutoML) extends beyond model selection to encompass automated data preparation and feature engineering. These systems apply learned heuristics and optimization techniques to clean data, handle missing values, detect outliers, and engineer features with minimal human intervention. While expert guidance remains valuable, AutoML democratizes access to sophisticated data preparation techniques for teams with limited data science expertise.
More Read: AI ROI Measurement: How to Calculate Return on Investment
Conclusion
AI training data quality fundamentally determines the success of machine learning initiatives, making systematic collection, preparation, and quality assurance essential competencies for AI-driven organizations. From data fundamentals through implementing robust validation methods, each stage of the training data lifecycle demands careful attention, specialized expertise, and appropriate tooling.
Organizations that invest in comprehensive data management practices, embrace emerging technologies like synthetic data and active learning, and maintain an unwavering commitment to data quality standards position themselves for sustained competitive advantage in the AI era. As the field continues evolving with innovations in self-supervised learning, federated approaches, and data-centric AI methodologies, the principles of quality, diversity, and ethical responsibility remain constant guideposts for building reliable, fair, and high-performing AI systems that deliver transformative value across industries and applications.