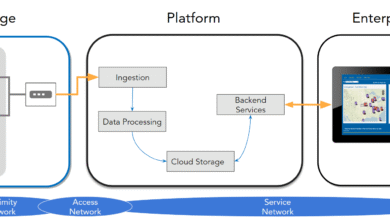
The rapid advancement of artificial intelligence has transformed how organizations approach computing infrastructure. As enterprises increasingly recognize the limitations of traditional on-premises data centers, Migrate AI Workloads to the cloud has emerged as a critical strategic initiative for 2025 and beyond. Recent industry research reveals that 64% of enterprises are investing heavily in AI technologies, with 63% accelerating their cloud migration plans to support these initiatives. This correlation isn’t coincidental—the cloud provides the scalable infrastructure, advanced computing resources, and flexible architecture that modern AI applications demand.
Migrate AI Workloads differs significantly from traditional application migration. Artificial intelligence systems require substantial computational power, massive data processing capabilities, specialized GPU acceleration, and dynamic resource allocation that conventional infrastructure simply cannot deliver efficiently. Machine learning models, deep learning frameworks, natural language processing applications, and computer vision systems all demand elastic scalability and high-performance computing environments that cloud platforms are uniquely positioned to provide.
The journey of migrating AI workloads to the cloud presents both tremendous opportunities and complex challenges. Organizations must navigate intricate technical requirements, address data governance concerns, optimize costs, ensure security compliance, and maintain performance standards throughout the migration process. Whether you’re moving existing AI models, deploying new machine learning pipelines, or building comprehensive AI platforms, the strategic approaches and best practices are essential for success.
This comprehensive guide explores proven methodologies for successful cloud migration of AI workloads. We’ll examine critical planning stages, assessment frameworks, migration strategies, security considerations, performance optimization techniques, and cost management approaches. From initial preparation through post-migration optimization, you’ll discover actionable insights to ensure your Migrate AI Workloads delivers maximum value while minimizing risks and disruptions to your business operations.
AI Workloads and Cloud Infrastructure
What Makes AI Workloads Unique
Migrate AI Workloads differ fundamentally from traditional enterprise applications in their resource consumption patterns and infrastructure requirements. These workloads typically involve computationally intensive operations such as training neural networks, processing large datasets, running inference engines, and executing complex algorithms that demand specialized hardware acceleration. Machine learning workloads often require Graphics Processing Units (GPUs), Tensor Processing Units (TPUs), or specialized AI accelerators that provide the parallel processing capabilities essential for efficient model training and deployment.
The unpredictable nature of Migrate AI Workloads resource demands creates additional complexity. During model training phases, computational requirements can spike dramatically, consuming massive amounts of processing power and memory for hours or days. Conversely, inference operations may require consistent but lower-level resources with strict latency requirements. This variability makes traditional capacity planning approaches inadequate and highlights why cloud infrastructure provides ideal solutions through elastic scaling and on-demand resource allocation.
Cloud Platform Capabilities for AI
Modern cloud platforms offer comprehensive ecosystems specifically designed to support artificial intelligence workloads. Major providers like Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform deliver specialized services including managed machine learning platforms, pre-trained AI models, automated machine learning (AutoML) tools, and integrated development environments optimized for AI application development and deployment.
Cloud computing environments provide access to cutting-edge hardware without capital expenditure requirements. Organizations can leverage the latest GPU generations, high-bandwidth networking, distributed storage systems, and containerization technologies that would be prohibitively expensive to maintain on-premises. Additionally, cloud providers continuously update their infrastructure, ensuring access to emerging technologies and performance improvements without additional investment.
Benefits of Migrate AI Workloads to the Cloud
Scalability and Flexibility
The primary advantage of Migrate AI Workloads to the cloud lies in unprecedented scalability. Cloud infrastructure enables organizations to scale computing resources dynamically based on actual demand, eliminating the constraints of fixed on-premises capacity. During intensive training sessions, teams can provision hundreds of GPU instances, then scale down immediately afterward—paying only for resources actually consumed. This elasticity fundamentally transforms how organizations approach AI development and deployment.


Cloud migration also provides geographical flexibility, allowing AI applications to operate closer to data sources and end users. Distributed cloud regions enable low-latency inference, improved user experiences, and compliance with data residency requirements. Organizations can deploy AI models across multiple regions simultaneously, ensuring high availability and disaster recovery capabilities that would require massive infrastructure investments on-premises.
Cost Optimization and Resource Efficiency
Despite concerns about cloud costs, properly managed AI workload migration typically delivers significant financial benefits. The shift from capital expenditure to operational expenditure eliminates large upfront hardware investments and reduces maintenance overhead. Organizations avoid the common problem of overprovisioning infrastructure for peak demands that occur infrequently, instead paying only for resources during actual usage periods.
Cloud platforms offer sophisticated cost management tools, including reserved instances, spot instances, and committed use discounts that can reduce AI workload expenses by 50-70% compared to on-demand pricing. Automated scaling policies ensure resources are allocated efficiently, preventing waste from idle capacity. Additionally, managed services reduce operational costs by eliminating the need for specialized infrastructure management expertise.
Access to Advanced AI Services
Cloud providers deliver managed artificial intelligence services that accelerate development timelines and reduce complexity. Pre-built AI capabilities, including computer vision APIs, natural language processing services, speech recognition, recommendation engines, and automated machine learning platforms, enable rapid prototyping and deployment without requiring deep expertise in every AI domain.
Integration with cloud-native services creates powerful synergies for AI applications. Seamless connections to data lakes, streaming analytics platforms, serverless computing, container orchestration, and DevOps tools create comprehensive ecosystems that streamline the entire AI lifecycle from data preparation through model deployment and monitoring.
Pre-Migration Assessment and Planning
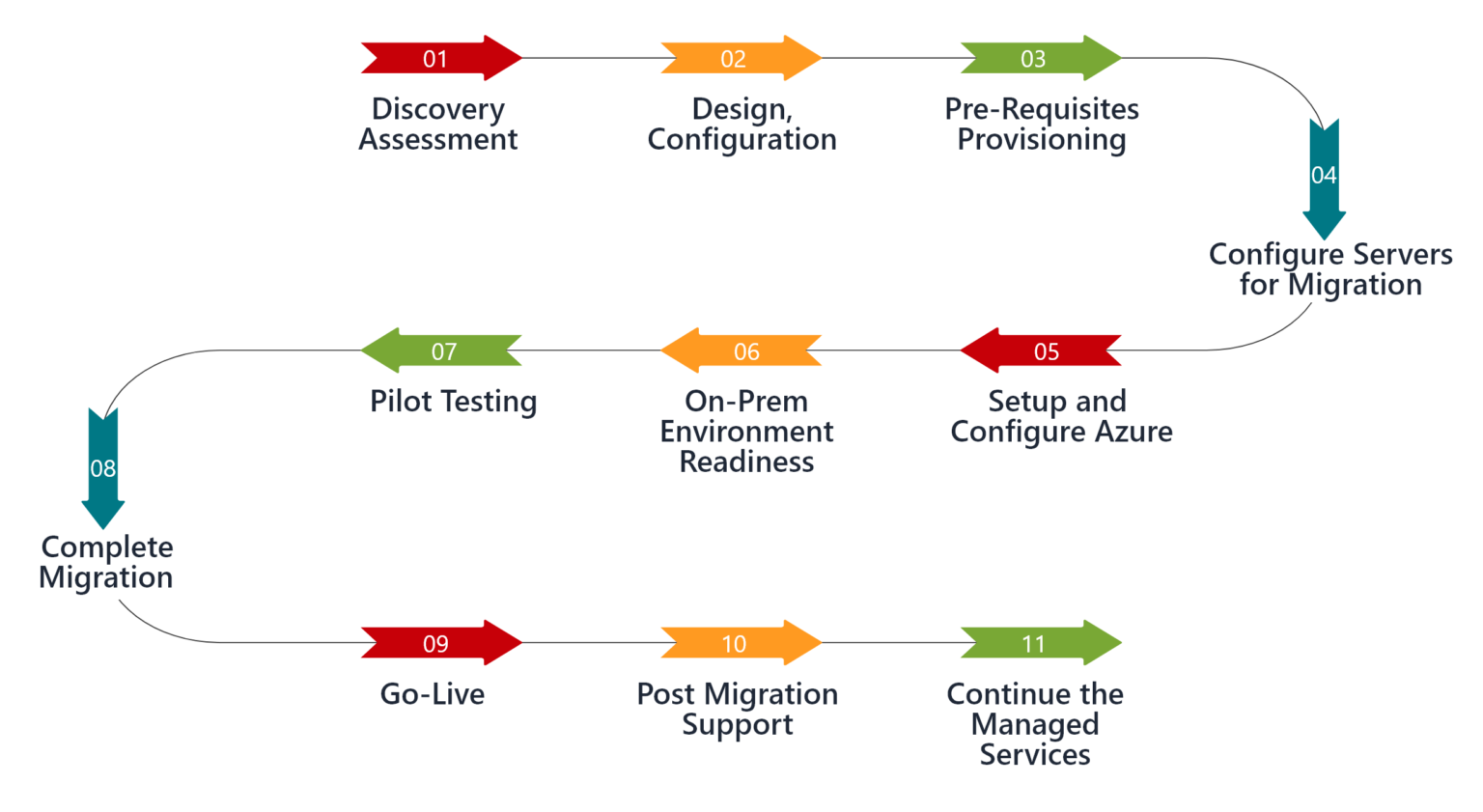
Workload Analysis and Categorization
Successful Migrate AI Workloads begins with a comprehensive assessment of existing systems. Organizations must catalog all AI applications, their technical requirements, dependencies, data flows, performance characteristics, and business criticality. This inventory should document computational requirements, storage needs, network bandwidth utilization, integration points, and compliance requirements for each workload.
Categorizing AI workloads based on migration complexity helps prioritize efforts and allocate resources effectively. Simple stateless inference services may migrate quickly using rehosting approaches, while complex distributed training pipelines might require significant rearchitecting. Identifying quick wins—workloads that deliver high value with minimal migration complexity—builds momentum and demonstrates early success.
Infrastructure Requirements Assessment
The specific infrastructure needs of Migrate AI Workloads are critical for selecting appropriate cloud services and architectures. Assessment should evaluate computational intensity, determining whether workloads benefit from GPU acceleration, specialized AI chips, or high-core-count CPUs. Memory requirements, storage IOPS demands, network throughput needs, and latency sensitivities all influence cloud platform selection and configuration decisions.
Data requirements deserve particular attention during assessment. Organizations must evaluate data volumes, access patterns, processing requirements, and movement costs. Where data currently resides, how AI models consume it, and regulatory constraints on data location guide decisions about cloud storage architectures, data migration strategies, and potential hybrid approaches.
Establishing Success Metrics
Defining clear success criteria before beginning cloud migration ensures objective evaluation and continuous improvement. Key performance indicators should encompass technical metrics like model training times, inference latency, throughput capacity, and system availability, alongside business metrics including cost per prediction, time-to-market for new models, and developer productivity improvements.
Baseline measurements of current on-premises performance provide comparison points for validating cloud migration success. Documenting existing training durations, inference response times, resource utilization patterns, and operational costs creates quantifiable targets for cloud deployments. Establishing acceptable performance thresholds prevents premature migration of workloads unsuitable for current cloud capabilities.
Selecting the Right Cloud Migration Strategy
The Seven Rs of Cloud Migration
The industry-standard migration strategies framework—known as the Seven Rs—provides structured approaches for different workload scenarios. These strategies help organizations select optimal paths for each AI application based on complexity, business requirements, and technical constraints.
Rehosting (lift-and-shift) involves moving AI workloads to the cloud with minimal modifications. This approach provides quick migration and immediate infrastructure benefits but may not leverage cloud-native advantages. It works well for legacy applications where rearchitecting isn’t justified or as an interim step toward future optimization.
Replatforming makes selective optimizations during migration without a complete redesign. For AI workloads, this might involve switching to managed databases, adopting container orchestration, or utilizing cloud-native storage while maintaining core application logic. This balanced approach captures significant cloud benefits without extensive redevelopment.
Refactoring or rearchitecting redesigns applications to fully exploit cloud capabilities. For AI systems, this could mean adopting serverless architectures, implementing microservices patterns, or utilizing managed machine learning platforms. While resource-intensive, refactoring delivers maximum long-term benefits, including improved scalability, reliability, and operational efficiency.
Repurchasing replaces existing applications with cloud-native SaaS alternatives. Organizations might abandon custom-built AI platforms in favor of comprehensive managed services from cloud providers. This strategy works when commercial offerings meet requirements and migration complexity outweighs customization benefits.
Choosing the Right Strategy for AI Workloads
AI workload characteristics should drive migration strategy selection. Training workloads with intermittent resource demands often benefit from rearchitecting to leverage spot instances and auto-scaling. Real-time inference services requiring consistent performance might start with replatforming to containerized deployments before eventual refactoring.
Consider also the maturity of AI applications. Experimental models and prototypes may warrant aggressive refactoring to cloud-native patterns, while production systems supporting critical business functions might require conservative rehosting approaches that minimize risk. Development stage, technical debt levels, and team capabilities all influence optimal strategy selection.
Hybrid and Multi-Cloud Approaches
Many organizations adopt hybrid strategies, retaining some AI workloads on-premises while migrating others to cloud platforms. Sensitive data processing, highly optimized systems, or workloads with strict latency requirements might remain in private data centers while development environments, batch processing, and scalable inference move to the cloud. This pragmatic approach balances cloud benefits against specific constraints.
Multi-cloud strategies distribute workloads across multiple cloud providers to avoid vendor lock-in, optimize costs, or leverage specialized capabilities. An organization might use one provider’s superior AI services for model development while deploying production inference on another provider’s cost-effective infrastructure. However, multi-cloud increases complexity and requires sophisticated orchestration capabilities.
Data Migration and Management Strategies
Data Assessment and Classification
Data forms the foundation of all AI applications, making a data migration strategy critical for successful cloud migration. Organizations must assess data volumes, understand growth rates, classify sensitivity levels, and map data dependencies across AI workloads. This assessment identifies which datasets require migration, acceptable transfer timeframes, and appropriate cloud storage services.
Data classification according to sensitivity, compliance requirements, and access patterns guides security controls and storage tier selection. Highly sensitive training data might require encryption, access auditing, and restricted regional storage. Frequently accessed datasets benefit from high-performance storage tiers, while archival data can utilize cost-effective cold storage options.
Data Transfer Methods and Tools
Transferring large datasets to cloud platforms requires careful planning to minimize costs and transfer times. For moderate data volumes, direct network transfer using high-speed connections provides simplicity and reasonable timelines. Cloud providers offer dedicated network services with higher bandwidth and lower latency than public internet connections.
For massive datasets measured in petabytes, physical transfer methods become practical necessities. Services like AWS Snowball, Azure Data Box, and Google Transfer Appliance enable organizations to ship encrypted storage devices directly to cloud data centers, bypassing network bandwidth limitations. These solutions dramatically reduce transfer times and costs for initial bulk migrations.
Ensuring Data Integrity and Security
Data integrity throughout migration prevents corrupted datasets from compromising AI model accuracy and reliability. Implementing checksums, validation scripts, and comparison tools verifies that transferred data matches source systems exactly. Automated validation processes catch errors early, preventing downstream problems in training pipelines and inference services.
Security during data migration requires encryption in transit and at rest, access controls, and audit logging. Establishing secure transfer channels using VPNs or dedicated connections protects sensitive information. Implementing cloud security best practices, including identity management, encryption key management, and network segmentation, ensures migrated data remains protected in new environments.
Security and Compliance Considerations
Implementing Cloud Security Best Practices
Cloud security for AI workloads demands comprehensive approaches encompassing identity management, network security, data protection, and threat detection. Implementing the principle of least privilege ensures users and services access only the required resources. Multi-factor authentication, role-based access control, and regular permission audits prevent unauthorized access to sensitive AI models and training data.
Network segmentation isolates AI workloads from other systems, limiting blast radius if breaches occur. Virtual private clouds, security groups, and network access control lists create defense-in-depth architectures. Implementing Web Application Firewalls (WAF) protects inference APIs from attacks, while intrusion detection systems monitor for suspicious activities across cloud infrastructure.
Data Protection and Privacy
AI applications often process personally identifiable information, making data protection paramount. Encryption at rest and in transit protects sensitive data throughout its lifecycle. Cloud platforms provide managed encryption services, key management systems, and integration with hardware security modules for enhanced protection.
Privacy considerations extend beyond encryption to include data anonymization, pseudonymization, and differential privacy techniques. Organizations training machine learning models on personal data must implement privacy-preserving methods that prevent models from memorizing and leaking sensitive information. Regular privacy impact assessments ensure AI systems comply with regulations like GDPR, CCPA, and industry-specific requirements.
Compliance and Regulatory Requirements
Different industries face varying compliance obligations affecting cloud migration decisions. Healthcare organizations must ensure HIPAA compliance, financial services require adherence to regulations like SOC 2 and PCI DSS, while government entities may have strict data sovereignty requirements. Applying applicable regulations before migration prevents costly remediation later.
Cloud providers offer compliance certifications and specialized regions meeting specific regulatory requirements. Leveraging these capabilities simplifies compliance efforts, though organizations remain responsible for proper configuration and usage. Implementing comprehensive audit logging, maintaining documentation, and conducting regular compliance assessments demonstrates due diligence.
Technical Implementation and Migration Process
Building the Cloud Foundation
Successful AI workload migration requires establishing robust cloud foundations before moving production systems. This includes configuring identity and access management systems, establishing network architectures, implementing monitoring and logging infrastructure, and setting up disaster recovery mechanisms. Creating landing zones—pre-configured environments following best practices—accelerates subsequent migrations.
Infrastructure-as-code approaches using tools like Terraform, CloudFormation, or Azure Resource Manager ensure consistent, repeatable deployments. Version-controlled infrastructure definitions document configurations, enable rapid environment replication, and facilitate disaster recovery. This foundation supports both initial migration and ongoing cloud operations.
Containerization and Orchestration
Containerizing AI applications using Docker or similar technologies provides consistency across development, testing, and production environments. Containers encapsulate AI models, dependencies, and runtime requirements, simplifying deployment and ensuring reproducibility. This approach particularly benefits machine learning workflows where environment consistency significantly impacts results.
Container orchestration platforms like Kubernetes manage containerized AI workloads at scale, handling deployment, scaling, load balancing, and health monitoring. Managed Kubernetes services from cloud providers reduce operational complexity while delivering enterprise-grade orchestration capabilities. Kubernetes enables sophisticated deployment patterns, including canary releases, A/B testing, and blue-green deployments for AI models.
Migration Execution Phases
Structured migration execution minimizes risks and ensures smooth transitions. The pilot phase migrates non-critical workloads to validate approaches, test infrastructure, and train teams without impacting production systems. Learning from pilot experiences informs refinements before larger-scale migrations.
Subsequent waves migrate increasingly critical AI workloads following proven patterns established during pilots. Phased approaches allow course corrections, prevent overwhelming teams, and maintain business continuity. Each wave should include thorough testing, performance validation, and rollback procedures in case issues arise.
Testing and Validation
Comprehensive testing validates that migrated AI workloads perform correctly in cloud environments. Functional testing confirms models produce expected results, integration testing verifies connections with dependent systems, and performance testing ensures response times and throughput meet requirements under various load conditions.
Validation extends beyond technical functionality to business outcomes. A/B testing compares predictions between on-premises and cloud-deployed models to confirm accuracy consistency. Monitoring key business metrics during and after migration detects any negative impacts requiring investigation and remediation.
Performance Optimization and Cost Management

Right-Sizing Cloud Resources
Optimal cloud performance requires matching resource allocations to actual workload requirements. Over-provisioning wastes money on unused capacity, while under-provisioning causes performance degradation and poor user experiences. Monitoring tools track CPU utilization, memory consumption, storage IOPS, and network throughput to inform right-sizing decisions.
AI workloads often exhibit distinct resource consumption patterns during training versus inference. Training typically demands powerful GPUs and substantial memory for hours or days, while inference requires consistent but lower resources with strict latency requirements. Tailoring instance types, storage configurations, and network setups to specific phases optimizes both performance and costs.
Leveraging Auto-Scaling and Spot Instances
Auto-scaling dynamically adjusts cloud resources based on actual demand, ensuring adequate capacity during peaks while reducing costs during quiet periods. For AI inference services experiencing variable request volumes, auto-scaling maintains response times while minimizing infrastructure costs. Properly configured scaling policies balance responsiveness against cost efficiency.
Spot instances offer significant cost savings—often 70-90% discounts compared to on-demand pricing—for workloads tolerating interruptions. Training machine learning models using spot instances dramatically reduces costs since training can resume from checkpoints after interruptions. Combining spot instances with on-demand or reserved capacity creates cost-effective, resilient architectures.
Monitoring and Cost Governance
Comprehensive monitoring tracks cloud spending, resource utilization, and performance metrics, providing visibility into optimization opportunities. Cost allocation tags attribute expenses to specific projects, teams, or AI applications, enabling accountability and informed budget decisions. Automated alerts notify teams when spending exceeds thresholds, preventing budget surprises.
Implementing cost governance policies prevents runaway spending while maintaining necessary flexibility. Approval workflows for expensive resources, automatic shutdown of non-production environments during off-hours, and regular reviews of underutilized resources all contribute to cost discipline without hindering innovation.
Post-Migration Optimization and Management
Continuous Performance Tuning
Cloud migration doesn’t end when workloads go live—ongoing optimization realizes full cloud benefits. Regular performance reviews identify bottlenecks, inefficient resource usage, and opportunities for improvement. Database query optimization, caching strategies, content delivery network implementation, and architecture refinements progressively enhance performance.
AI model performance requires specific attention, including monitoring prediction accuracy, inference latency, and model drift over time. Retraining schedules, A/B testing new model versions, and gradual rollout strategies ensure AI applications maintain quality while incorporating improvements. Automated monitoring detects performance degradation requiring investigation.
Implementing Cloud-Native Practices
Transitioning to cloud-native operational practices maximizes cloud platform value. Embracing DevOps methodologies, continuous integration/continuous deployment pipelines, and infrastructure-as-code transforms how teams develop and deploy AI applications. These practices accelerate development cycles, improve reliability, and reduce operational overhead.
Adopting managed services progressively reduces undifferentiated heavy lifting. Migrating from self-managed databases to managed services, replacing custom job schedulers with cloud-native alternatives, and utilizing serverless computing where appropriate allows teams to focus on AI innovation rather than infrastructure management.
Disaster Recovery and Business Continuity
Robust disaster recovery plans protect AI workloads against service disruptions, data loss, and regional outages. Cloud platforms facilitate sophisticated disaster recovery strategies, including automated backups, cross-region replication, and rapid failover capabilities. Regular testing validates that recovery procedures work correctly and meet recovery time objectives.
Documentation of recovery procedures, maintenance of updated runbooks, and training ensure teams can execute disaster recovery plans effectively during actual incidents. Automated recovery, where possible, reduces human error and accelerates restoration of services.
Common Challenges and Solutions
Managing Technical Complexity
AI workload migration involves substantial technical complexity, including dependency mapping, data synchronization, performance tuning, and integration testing. Breaking migrations into manageable phases, maintaining detailed documentation, and conducting thorough testing mitigate complexity risks. Partnering with experienced cloud migration specialists accelerates timelines and improves outcomes.
Legacy system dependencies create particular challenges when modernizing AI infrastructure. Identifying and documenting all integration points before migration prevents unexpected failures. Implementing API gateways, message queues, and adapter patterns facilitates the gradual decoupling of AI workloads from legacy systems.
Addressing Skills Gaps
Cloud technologies require different skillsets than traditional on-premises infrastructure. Organizations must invest in training existing teams, hiring cloud-experienced talent, or partnering with managed service providers. Certification programs from cloud providers, hands-on workshops, and mentorship accelerate capability building.
Establishing centers of excellence creates knowledge repositories and best practice sharing mechanisms. Cloud champions within teams drive adoption, answer questions, and identify optimization opportunities. Balancing internal capability development against strategic partnerships ensures adequate expertise throughout migration journeys.
Overcoming Organizational Resistance
Cultural and organizational factors often impede cloud adoption more than technical obstacles. Addressing concerns about job security, demonstrating value through pilot successes, and involving stakeholders in planning builds support. Clear communication about migration rationale, expected benefits, and roadmaps reduces uncertainty and resistance.
Executive sponsorship proves critical for overcoming organizational inertia and securing necessary resources. Leadership commitment signals strategic importance, facilitates cross-functional collaboration, and empowers teams to make necessary changes. Regular progress updates to leadership maintain momentum and enable rapid problem resolution.
Future Trends in AI Cloud Migration
Edge Computing and Hybrid AI Architectures
The proliferation of edge computing extends cloud capabilities to network edges, enabling low-latency AI inference for applications like autonomous vehicles, augmented reality, and IoT systems. Hybrid architectures split AI workloads between centralized cloud platforms for training and edge devices for inference, balancing performance, latency, and cost requirements.
Cloud providers increasingly offer edge computing services that integrate seamlessly with central cloud platforms. These services enable consistent management, deployment, and monitoring across distributed infrastructure. Organizations can develop AI models centrally and then deploy them to thousands of edge locations automatically.
Specialized AI Accelerators
Cloud platforms continue expanding specialized hardware options optimized for AI workloads. Custom AI chips like Google’s TPUs, AWS Inferentia and Trainium, and Azure’s Maia deliver superior performance and cost efficiency compared to general-purpose GPUs. Access to cutting-edge acceleration without capital investment remains a compelling cloud migration driver.
Future accelerators will support emerging AI paradigms, including neuromorphic computing, quantum-inspired algorithms, and brain-computer interfaces. Cloud infrastructure democratizes access to these technologies, allowing organizations of all sizes to experiment with and adopt advanced capabilities as they mature.
Sustainable AI and Green Computing
Environmental considerations increasingly influence cloud migration decisions. Cloud providers invest heavily in renewable energy, efficient cooling systems, and carbon-neutral operations. Migrating AI workloads to efficient cloud infrastructure often reduces carbon footprints compared to on-premises data centers with older, less efficient hardware.
Organizations prioritizing sustainability can leverage cloud platforms committed to environmental responsibility. Choosing regions powered by renewable energy, optimizing model efficiency to reduce computational requirements, and scheduling training jobs during periods of clean energy availability all contribute to more sustainable AI operations.
More Read: Cloud AI Services Comparison AWS vs Azure vs Google Cloud
Conclusion
Successfully migrating AI workloads to the cloud represents a strategic imperative for organizations seeking competitive advantages through artificial intelligence. The cloud provides unmatched scalability, access to specialized infrastructure, cost flexibility, and managed services that accelerate AI development and deployment. However, realizing these benefits requires careful planning, strategic execution, and ongoing optimization. Organizations must thoroughly assess their workloads, select appropriate migration strategies, address security and compliance requirements, and establish robust operational practices.
By following proven methodologies, leveraging cloud-native capabilities, and maintaining focus on business outcomes rather than technology alone, enterprises can transform their AI capabilities while managing costs and risks effectively. The journey may be complex, but with proper preparation and execution, cloud migration unlocks unprecedented opportunities for innovation, scale, and business value from artificial intelligence initiatives. As cloud technologies continue evolving with new AI-specific capabilities, early adopters of comprehensive cloud migration strategies will find themselves best positioned to capitalize on emerging opportunities and maintain competitive advantages in increasingly AI-driven markets.