Machine Learning Algorithms Explained for Beginners
Learn machine learning algorithms easily! Complete beginner's guide covering supervised, unsupervised & reinforcement learning with practical
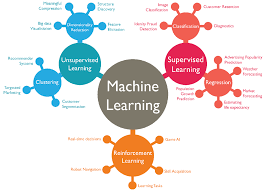
Machine learning algorithms have revolutionized how we process data and make predictions in today’s digital landscape. Whether you’re browsing social media feeds, shopping online, or using navigation apps, machine learning quietly powers these experiences behind the scenes. For beginners entering this fascinating field, the fundamental types of machine learning algorithms serves as the cornerstone for building expertise in artificial intelligence and data science.
The world of machine learning algorithms explained can initially seem overwhelming, with complex mathematical concepts and technical jargon creating barriers for newcomers. However, breaking down these algorithms into digestible concepts makes the learning journey both manageable and exciting. This comprehensive guide will walk you through the essential machine learning algorithms for beginners, providing clear explanations, practical examples, and real-world applications that demonstrate their power and versatility.
Supervised learning algorithms, unsupervised learning, and reinforcement learning represent the three primary categories that form the foundation of modern AI systems. Each category serves distinct purposes and tackles different types of problems, from predicting house prices to discovering hidden patterns in customer behavior. These algorithm types empower you to choose the right tool for specific data science challenges and open doors to exciting career opportunities in technology, finance, healthcare, and beyond.
Throughout this guide, we’ll explore popular algorithms like linear regression, decision trees, neural networks, and clustering algorithms, explaining not just how they work, but when and why to use them. By the end of this article, you’ll have a solid foundation in machine learning fundamentals and the confidence to begin your journey into this transformative field that’s reshaping industries worldwide.
What Are Machine Learning Algorithms
Machine learning algorithms are sophisticated mathematical models that enable computers to learn from data without being explicitly programmed for every possible scenario. Think of them as digital pattern recognition systems that can identify relationships, make predictions, and adapt their behavior based on the information they process. Unlike traditional programming where developers write specific instructions, machine learning allows systems to improve their performance automatically through experience.
At their core, these algorithms work by analyzing large datasets to discover hidden patterns and relationships that humans might miss or find too complex to identify manually. They process input data, apply mathematical transformations, and generate outputs in the form of predictions, classifications, or insights. The beauty of machine learning algorithms explained lies in their ability to generalize from training examples to make accurate predictions on new, unseen data.
The machine learning process typically involves several key stages: data collection, preprocessing, model training, evaluation, and deployment. During training, algorithms adjust their internal parameters based on the patterns they discover in the training data. This learning process enables them to make increasingly accurate predictions as they encounter more examples, making them incredibly powerful tools for solving complex real-world problems.
Data science professionals use these algorithms across diverse applications, from recommending products on e-commerce platforms to detecting fraudulent transactions in banking systems. The versatility of machine learning algorithms makes them indispensable in modern technology, driving innovations in autonomous vehicles, medical diagnosis, natural language processing, and countless other domains that impact our daily lives.
Types of Machine Learning Algorithms
Supervised Learning Algorithms
Supervised learning algorithms represent the most intuitive category of machine learning for beginners to understand. These algorithms learn from labeled training data, where both input features and correct output answers are provided during the training process. Like a student learning with answer sheets, supervised learning algorithms analyze the relationship between inputs and known outputs to make accurate predictions on new, unlabeled data.


The Machine Learning Algorithms approach works exceptionally well for problems where historical data with known outcomes is available. For example, if you want to predict house prices, you would train the algorithm using historical data containing house features (size, location, bedrooms) paired with their actual selling prices. The algorithm learns to map these features to prices, enabling it to predict values for new properties.
Classification algorithms and regression algorithms form the two main subcategories of supervised learning. Classification algorithms predict discrete categories or classes, such as determining whether an email is spam or legitimate. Popular classification algorithms include decision trees, support vector machines, and logistic regression, each offering unique advantages for different types of problems.
Regression algorithms, on the other hand, predict continuous numerical values like stock prices, temperatures, or sales figures. Linear regression serves as the foundation of regression analysis, while more advanced techniques like polynomial regression and random forest regression handle complex, non-linear relationships in data. These distinctions helps beginners choose appropriate algorithms for their specific machine learning projects.
Unsupervised Learning Algorithms
Unsupervised learning algorithms tackle the challenging task of finding hidden patterns in data without labeled examples or known correct answers. Unlike supervised learning, these algorithms explore datasets independently, discovering structures, relationships, and groupings that weren’t explicitly programmed or anticipated. This makes unsupervised learning particularly valuable for exploratory data analysis and discovering insights in complex datasets.
Clustering algorithms represent the most common type of unsupervised learning, automatically grouping similar data points based on their characteristics. K-means clustering, one of the most popular clustering algorithms, partitions data into distinct groups by minimizing the distance between data points within each cluster. Businesses use clustering to segment customers, identify market segments, and organize products based on similarity.
Dimensionality reduction algorithms tackle the challenge of working with high-dimensional data by reducing the number of features while preserving important information. Principal Component Analysis (PCA) exemplifies this approach, transforming complex datasets into simpler representations that maintain the most significant patterns. This technique proves invaluable when visualizing high-dimensional data or improving the performance of other machine learning algorithms.
Association rule learning discovers relationships between different variables in large datasets, famously used in market basket analysis to understand customer purchasing patterns. The classic example “customers who buy bread also buy butter” demonstrates how unsupervised learning reveals hidden connections that can drive business decisions, recommendation systems, and inventory management strategies.
Reinforcement Learning
Reinforcement learning represents the most dynamic and interactive category of machine learning algorithms, where agents learn optimal behaviors through trial and error in an environment. Unlike supervised learning with labeled data or unsupervised learning with pattern discovery, reinforcement learning focuses on learning through actions, rewards, and penalties, mimicking how humans and animals learn from experience.
The reinforcement learning process involves an agent taking actions in an environment, receiving feedback in the form of rewards or penalties, and adjusting its strategy to maximize cumulative rewards over time. This approach excels in scenarios where the optimal solution isn’t immediately apparent and must be discovered through exploration and experimentation, such as game playing, robotics, and autonomous vehicle control.
Q-learning and policy gradient methods represent fundamental reinforcement learning algorithms that have achieved remarkable success in complex domains. These algorithms enable AI systems to master games like Chess and Go at superhuman levels, control robotic systems with precision, and optimize resource allocation in dynamic environments. The ability to learn from interaction makes reinforcement learning particularly powerful for real-world applications where conditions change over time.
Applications of reinforcement learning extend far beyond gaming, encompassing financial trading algorithms, recommendation systems that adapt to user preferences, and industrial automation systems that optimize production processes. The self-improving nature of reinforcement learning algorithms makes them ideal for scenarios where traditional programming approaches fall short and adaptive, intelligent behavior is required.
Popular Machine Learning Algorithms for Beginners
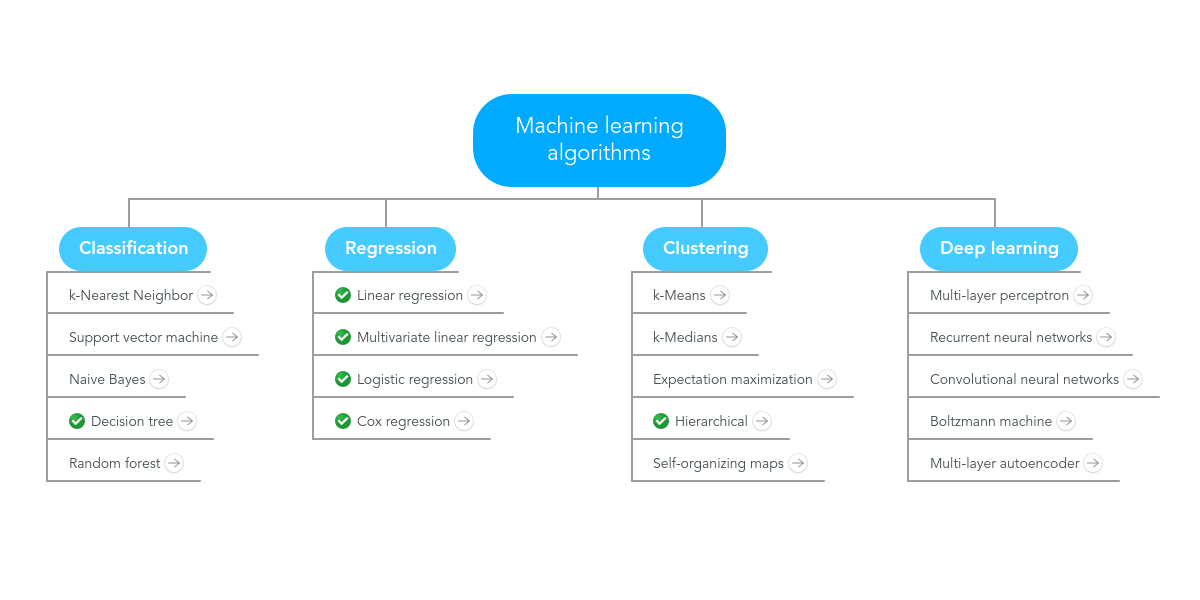
Linear Regression
Linear regression stands as the cornerstone of machine learning algorithms for beginners, offering an intuitive introduction to predictive modeling concepts. This fundamental algorithm establishes a linear relationship between input variables (features) and a continuous target variable, making it perfect for how machine learning transforms data into predictions. The simplicity of linear regression allows newcomers to grasp essential concepts without getting overwhelmed by mathematical complexity.
The linear regression algorithm works by finding the best-fitting straight line through data points, minimizing the difference between predicted and actual values. This process involves calculating coefficients that define the relationship between each input feature and the target output. For example, predicting house prices based on size creates a linear equation where the coefficient represents how much the price increases for each additional square foot.
Simple linear regression uses one input variable, while multiple linear regression incorporates several features to make more accurate predictions. These variations helps beginners appreciate how machine learning algorithms can handle increasingly complex scenarios. The interpretability of linear regression makes it valuable not just for predictions but also for which factors most significantly impact the target variable.
Regression analysis using linear models provides excellent training ground for learning fundamental machine learning concepts like training, testing, overfitting, and model evaluation. Many advanced algorithms build upon these basic principles, making linear regression an essential starting point for anyone serious about mastering machine learning algorithms explained.
Decision Trees
Decision trees offer one of the most intuitive machine learning algorithms for beginners due to their human-readable structure that mirrors natural decision-making processes. These algorithms create a tree-like model of decisions, where each internal node represents a test on a feature, each branch represents the outcome of that test, and each leaf node represents a class label or numerical value. This visual representation makes decision trees exceptionally easy to understand and explain to non-technical stakeholders.
The decision tree algorithm works by recursively splitting the dataset based on features that provide the most information gain or reduction in impurity. At each node, the algorithm evaluates all possible splits and chooses the one that best separates the data according to the target variable. This process continues until the tree reaches a stopping criterion, such as maximum depth or minimum samples per leaf.
Classification trees predict categorical outcomes, such as determining whether a loan applicant will default, while regression trees predict continuous values like predicting a person’s income based on their characteristics. The versatility of decision trees makes them applicable to numerous machine learning problems across various domains, from medical diagnosis to customer segmentation.
One of the greatest advantages of decision trees lies in their interpretability and ability to handle both numerical and categorical features without extensive preprocessing. However, beginners should understand that decision trees can easily overfit to training data, leading to poor generalization on new examples. This limitation introduces important concepts like pruning and ensemble methods that build upon basic decision tree algorithms.
Neural Networks
Neural networks represent the foundation of modern artificial intelligence and deep learning, inspired by the structure and function of biological neural systems. For beginners, neural networks opens doors to the most exciting and rapidly advancing areas of machine learning, from image recognition to natural language processing. These algorithms consist of interconnected nodes (neurons) organized in layers that process information in a way loosely modeled after the human brain.
The basic neural network architecture includes an input layer, one or more hidden layers, and an output layer. Each connection between neurons carries a weight that determines the strength of the signal passed between nodes. During training, the neural network algorithm adjusts these weights based on the errors between predicted and actual outputs, gradually learning to make more accurate predictions through a process called backpropagation.
Feedforward neural networks provide the simplest introduction to neural network concepts, where information flows in one direction from input to output. As beginners master these fundamentals, they can explore more advanced architectures like convolutional neural networks for image processing and recurrent neural networks for sequential data analysis. These building blocks prepares newcomers for the exciting world of deep learning.
The power of neural networks lies in their ability to learn complex, non-linear patterns that simpler machine learning algorithms might miss. However, this capability comes with increased complexity in terms of training time, data requirements, and parameter tuning. For beginners, starting with small neural networks on simple problems provides valuable hands-on experience with these transformative algorithms.
K-Means Clustering
K-means clustering serves as an excellent introduction to unsupervised learning algorithms, demonstrating how machine learning can discover hidden patterns in data without labeled examples. This clustering algorithm groups data points into k clusters based on similarity, where k represents the number of groups specified by the user. The intuitive nature of K-means makes it perfect for beginners to understand unsupervised learning concepts.
The K-means algorithm works through an iterative process that alternates between two steps: assigning data points to the nearest cluster center (centroid) and updating cluster centers based on the average position of assigned points. This process continues until cluster assignments stabilize or reach a maximum number of iterations. The simplicity of this approach makes K-means clustering both easy to understand and computationally efficient.
Cluster analysis using K-means finds applications across numerous domains, from customer segmentation in marketing to image segmentation in computer vision. Beginners can easily visualize how the algorithm works with two-dimensional data, watching as cluster centers move and data points reorganize into distinct groups. This visual learning experience reinforces fundamental machine learning concepts about optimization and convergence.
K-means clustering introduces beginners to important considerations in unsupervised learning, such as choosing the optimal number of clusters, handling different cluster shapes and sizes, and evaluating clustering quality. These concepts lay the groundwork for exploring more advanced clustering algorithms and other unsupervised learning techniques that expand the toolkit for analyzing complex datasets.
How Machine Learning Algorithms Work
Machine learning algorithms operate through a systematic process that transforms raw data into actionable insights and predictions. This machine learning process helps beginners appreciate the methodology behind successful AI applications and provides a roadmap for implementing their own projects. The journey from data to predictions involves several critical stages that each play a vital role in algorithm performance.
The data preprocessing stage forms the foundation of successful machine learning, where raw data is cleaned, transformed, and prepared for algorithm consumption. This crucial step involves handling missing values, removing outliers, scaling features to similar ranges, and converting categorical variables into numerical formats. Poor data preprocessing can severely impact algorithm performance, making this stage as important as algorithm selection itself.
Model training represents the core learning phase where algorithms analyze training data to discover patterns and relationships. During this process, machine learning algorithms adjust their internal parameters to minimize prediction errors on the training dataset. The quality and quantity of training data directly influence how well algorithms can learn and generalize to new, unseen examples.
Model evaluation and validation ensure that trained algorithms perform well on new data beyond the training set. Techniques like cross-validation and holdout testing help assess algorithm performance objectively and detect problems like overfitting, where models memorize training data but fail to generalize. Evaluation metrics enables beginners to measure and improve their machine learning models effectively.
Choosing the Right Algorithm
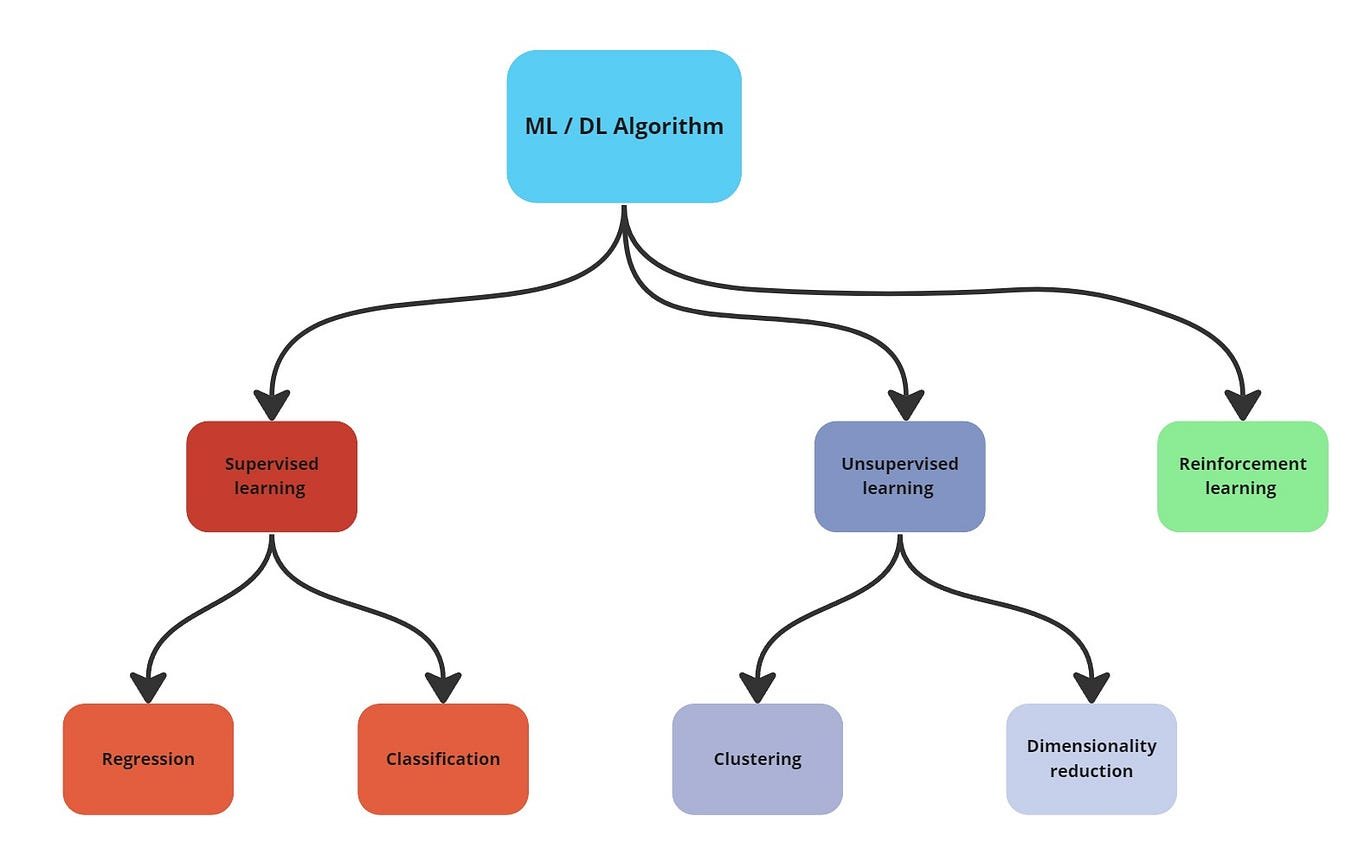
Selecting appropriate machine learning algorithms requires both the problem characteristics and algorithm strengths and limitations. For beginners, developing this decision-making skill is crucial for successful machine learning projects and avoiding common pitfalls that lead to poor results. The choice between supervised learning, unsupervised learning, or reinforcement learning depends on the available data and desired outcomes.
Problem type serves as the primary factor in algorithm selection, with different approaches suited to classification, regression, clustering, or optimization tasks. Classification algorithms work best for predicting categories or classes, while regression algorithms excel at predicting continuous numerical values. These distinctions helps beginners narrow down their options and focus on relevant algorithm types.
Dataset characteristics significantly influence algorithm performance and suitability. Small datasets favor simpler algorithms like linear regression or decision trees, while large datasets can benefit from more complex approaches like neural networks or ensemble methods. The number of features, presence of missing values, and data distribution patterns all impact algorithm choice and performance.
Computational resources and interpretability requirements provide practical constraints that influence algorithm selection. Simple algorithms like linear regression offer high interpretability but may lack predictive power for complex problems. Conversely, neural networks can model complex relationships but require more computational resources and offer less interpretability. Balancing these trade-offs is essential for successful machine learning implementation.
Real-World Applications
Machine learning algorithms have transformed numerous industries and daily experiences, demonstrating their practical value beyond academic theory. These real-world applications helps beginners appreciate the impact and potential of machine learning while inspiring ideas for their own projects. From healthcare to entertainment, algorithms solve complex problems and create value across diverse domains.
Healthcare applications showcase how machine learning saves lives and improves patient outcomes through medical image analysis, drug discovery, and personalized treatment recommendations. Classification algorithms help radiologists detect cancer in medical scans, while predictive models identify patients at risk for various conditions. These applications demonstrate the profound social impact that machine learning algorithms can achieve when applied thoughtfully.
E-commerce platforms rely heavily on recommendation systems powered by machine learning to personalize user experiences and increase sales. Collaborative filtering algorithms analyze user behavior patterns to suggest products, while clustering algorithms segment customers for targeted marketing campaigns. These applications illustrate how unsupervised learning and supervised learning work together to create sophisticated business solutions.
Financial services leverage machine learning algorithms for fraud detection, risk assessment, and algorithmic trading. Anomaly detection algorithms identify suspicious transactions in real-time, while regression models assess loan default risks. The high-stakes nature of financial applications demonstrates the reliability and accuracy that modern machine learning algorithms can achieve with proper implementation and validation.
Common Challenges for Beginners
Overfitting represents one of the most common challenges beginners face when learning machine learning algorithms. This problem occurs when models learn training data too well, memorizing specific examples rather than generalizing to new data. Overfitting and techniques to prevent it, such as regularization and cross-validation, is essential for developing robust machine learning models that perform well in real-world scenarios.
Data quality issues frequently frustrate newcomers who expect algorithms to work magic with poor-quality data. Missing values, inconsistent formatting, and biased samples can significantly impact algorithm performance. Learning proper data preprocessing techniques and the principle “garbage in, garbage out” helps beginners set realistic expectations and develop better machine learning practices.
Algorithm selection confusion often overwhelms beginners faced with numerous machine learning algorithms and conflicting advice about which approach to use. The key lies in problem requirements, data characteristics, and algorithm assumptions rather than searching for a universally “best” algorithm. Developing systematic approaches to algorithm evaluation and comparison helps beginners make informed decisions.
Performance evaluation mistakes can lead beginners to incorrect conclusions about algorithm effectiveness. Common errors include using inappropriate metrics, inadequate validation techniques, or misinterpreting results. Learning proper evaluation methodologies and metrics like accuracy, precision, recall, and F1-score enables beginners to assess their machine learning models accurately and make informed improvements.
Getting Started: Tools and Resources
Python has emerged as the dominant programming language for machine learning, offering extensive libraries and tools that simplify algorithm implementation. Scikit-learn provides user-friendly implementations of most common machine learning algorithms, while Pandas handles data manipulation and Matplotlib creates visualizations. These tools enable beginners to focus on machine learning concepts rather than struggling with low-level programming details.
Online learning platforms offer structured paths for mastering machine learning algorithms explained through interactive courses and hands-on projects. Platforms like Coursera, edX, and Udacity provide comprehensive curricula that combine theoretical knowledge with practical implementation skills. Many courses include real-world datasets and projects that reinforce machine learning fundamentals through experience.
Open datasets provide excellent opportunities for beginners to practice machine learning algorithms on realistic problems without the complexity of data collection and cleaning. Resources like Kaggle, UCI Machine Learning Repository, and Google Dataset Search offer thousands of curated datasets across various domains. Working with these datasets helps beginners understand how algorithms perform on different types of problems.
Community resources and documentation accelerate learning by providing answers to common questions and best practices developed by experienced practitioners. Stack Overflow, Reddit’s machine learning communities, and official library documentation offer valuable support for beginners encountering challenges. Engaging with these communities helps newcomers learn from others’ experiences and contribute to the broader machine learning ecosystem.
More Read: How to Start a Career in AI and Machine Learning: A Beginner’s Guide
Conclusion
Machine learning algorithms represent powerful tools that are reshaping our world through intelligent automation and data-driven insights. This comprehensive guide has introduced the fundamental types of machine learning algorithms, from supervised learning methods like linear regression and decision trees to unsupervised learning techniques like K-means clustering, along with the dynamic field of reinforcement learning.
These algorithm types provides beginners with a solid foundation for exploring more advanced topics and developing practical solutions to real-world problems. As you continue your machine learning journey, remember that success comes through consistent practice, experimentation with different algorithms, and staying curious about the endless possibilities that these transformative technologies offer across industries and applications.









