Supervised vs Unsupervised Learning: Simple Explanation
Learn the key differences between supervised vs unsupervised learning, their algorithms, applications, and how they transform data science and AI.

Machine learning has revolutionized how we process data and make predictions in the digital age. At its core, machine learning comprises two fundamental approaches: supervised learning and unsupervised learning. These two methodologies form the foundation of artificial intelligence systems used across industries, from healthcare diagnostics to financial forecasting and recommendation engines.
The primary distinction between supervised learning and unsupervised learning lies in the nature of training data. Supervised learning algorithms work with labeled data, where each input comes with a corresponding correct output, enabling models to learn precise relationships between inputs and desired outcomes. In contrast, unsupervised learning algorithms operate on unlabeled data, allowing them to discover hidden patterns and structures without predefined guidance. Understanding these fundamental differences is crucial for data scientists, machine learning engineers, and AI professionals who need to select the appropriate approach for their specific use cases.
Whether you’re predicting house prices, classifying emails as spam, or discovering customer segments, the choice between supervised vs unsupervised learning determines your model’s architecture, training time, and ultimately, its success. This comprehensive guide explores both approaches, examining their key differences, popular algorithms, real-world applications, and best practices for implementation. By the end of this article, you’ll have a clear understanding of which learning paradigm suits your data analysis needs.
What is Supervised Learning?
Supervised learning is a machine learning approach where models are trained on labeled datasets. In this paradigm, each training example consists of input features paired with known output labels or target variables. The term “supervised” reflects the guidance provided by these labeled examples during the training process.
In supervised learning algorithms, the model learns by identifying patterns that correlate input features with their corresponding outputs. This mapping function enables the model to predict outputs for new, unseen data with reasonable accuracy. Think of it as learning with a teacher who provides correct answers—the model adjusts itself iteratively to minimize prediction errors.
Supervised learning finds applications in classification problems, where the goal is to assign categorical labels to new inputs, and regression problems, which predict continuous numerical values. This approach requires substantial upfront effort to create well-labeled datasets but delivers highly accurate predictions when properly implemented.
Key Characteristics of Supervised Learning

- Labeled Training Data: Supervised learning requires datasets where each input example has been paired with its correct output label. Creating these labeled datasets demands significant time, resources, and expertise to ensure accuracy and reduce human bias.
- Defined Output Variables: The target variable is explicitly known before training begins. Whether predicting disease diagnosis, stock prices, or email categories, the model knows what it’s trying to predict from the start.
- Direct Feedback Mechanism: Supervised learning algorithms receive immediate feedback during training. If a prediction is incorrect, the model’s parameters are adjusted to improve accuracy on subsequent iterations.
- Higher Accuracy Potential: Because models learn from labeled examples showing correct answers, supervised learning typically achieves higher accuracy rates compared to unsupervised learning, especially for well-defined problems with quality training data.
What is Unsupervised Learning?
- Unsupervised learning represents a fundamentally different machine learning paradigm. Rather than learning from labeled data with predefined correct answers, unsupervised learning algorithms discover patterns and structures within unlabeled datasets independently. The model explores data without external guidance, identifying hidden relationships that humans might overlook.
- Unsupervised learning excels at exploratory data analysis and pattern discovery. When you have vast amounts of raw data but limited knowledge about underlying structures, unsupervised learning algorithms automatically identify meaningful groupings, correlations, and associations. This capability makes unsupervised learning invaluable for data preprocessing, anomaly detection, and generating insights from unstructured information.
The primary challenge with unsupervised learning is validating results. Since there are no correct answers to compare against, determining whether discovered patterns are meaningful or merely artifacts of the data requires careful analysis and domain expertise.
Key Characteristics of Unsupervised Learning
- Unlabeled Input Data: Unsupervised learning works exclusively with data lacking labels or predetermined categories. The model receives only input features without corresponding output values, forcing it to independently discover the data structure.
- Pattern Discovery: The fundamental goal of unsupervised learning is to identify hidden patterns, clusters, and relationships within data. Rather than predicting specific outputs, these algorithms reveal how data naturally organizes itself.
- No Predefined Targets: Unsupervised learning algorithms don’t optimize toward known objectives. Instead, they explore data comprehensively, revealing associations that might be valuable for business strategy or further analysis.
- Flexible and Scalable: Unsupervised learning handles vast unlabeled datasets efficiently, making it practical for real-world scenarios where labeling data would be prohibitively expensive or time-consuming.
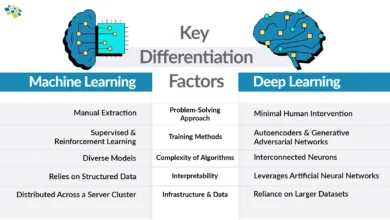
Main Differences Between Supervised and Unsupervised Learning
- Data Labeling Requirements: The fundamental distinction between supervised learning vs unsupervised learning centers on data labels. Supervised learning demands thoroughly labeled training datasets, while unsupervised learning operates on completely unlabeled data.
- Learning Objectives: Supervised learning algorithms aim to predict specific outputs based on learned input-output relationships. Unsupervised learning algorithms seek to discover underlying data structures without predefined targets.
- Algorithm Guidance: Supervised learning provides continuous feedback through labeled examples, guiding model development. Unsupervised learning offers no such guidance—the algorithm must independently determine valuable patterns.
- Performance Evaluation: Supervised learning models are evaluated against known correct answers, enabling straightforward accuracy measurements. Unsupervised learning evaluation requires qualitative analysis and domain expertise to assess pattern meaningfulness.
- Computational Requirements: Supervised learning often demands less data volume but requires extensive preprocessing and labeling. Unsupervised learning typically needs larger datasets but avoids labeling expenses.
- Real-World Applications: Supervised learning excels in prediction tasks like fraud detection, medical diagnosis, and price forecasting. Unsupervised learning dominates in customer segmentation, market research, and anomaly detection.
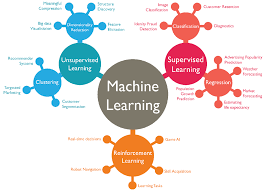
Common Supervised Learning Algorithms
- Classification Algorithms: These supervised learning algorithms predict categorical outputs. Logistic Regression models the probability of binary classification using sigmoid functions. Decision Trees create hierarchical structures for classification through feature-based splits. Random Forest combines multiple decision trees for improved accuracy. Support Vector Machines (SVM) find optimal decision boundaries in high-dimensional spaces.
- Regression Algorithms: These supervised learning methods predict continuous numerical values. Linear Regression models relationships between independent and dependent variables. Polynomial Regression captures non-linear relationships. Ridge Regression and Lasso Regression prevent overfitting through regularization.
- Neural Networks: Supervised learning leverages neural networks for complex pattern recognition. Multilayer Perceptrons (MLPs) use multiple layers to learn intricate relationships, excelling in image classification and natural language processing.
- Ensemble Methods: These techniques combine multiple models for enhanced performance. Gradient Boosting sequentially builds models, correcting previous errors. XGBoost (Extreme Gradient Boosting) adds regularization for faster, more accurate predictions on large datasets.
Common Unsupervised Learning Algorithms
- Clustering Algorithms: These unsupervised learning techniques group similar data points together. K-Means Clustering partitions data into specified cluster numbers based on similarity. Hierarchical Clustering creates dendrogram structures showing cluster relationships. DBSCAN identifies density-based clusters of arbitrary shapes.
- Dimensionality Reduction: These unsupervised learning methods simplify data while preserving information. Principal Component Analysis (PCA) reduces feature dimensions while maintaining variance. t-SNE visualizes high-dimensional data in lower dimensions effectively.
- Association Rule Mining: These techniques discover relationships between variables. Apriori Algorithm identifies frequent itemsets and association rules, commonly used in market basket analysis.
- Generative Models: These unsupervised learning approaches learn data distributions. Gaussian Mixture Models (GMMs) model data as a mixture of Gaussian distributions. Autoencoders compress and reconstruct data, useful for feature learning.
Real-World Applications of Supervised Learning
- Email Spam Detection: Supervised learning models trained on labeled emails (spam vs. legitimate) classify incoming messages accurately, protecting users from unwanted content.
- Medical Diagnosis: Supervised learning algorithms analyze patient data with known diagnoses to predict disease presence or severity, supporting clinical decision-making.
- Price Prediction: Regression models trained on historical data predict house prices, stock values, and product costs based on relevant features.
- Image Recognition: Supervised learning powers facial recognition, object detection, and autonomous vehicle perception systems through classification algorithms.
- Credit Risk Assessment: Supervised learning evaluates loan applicants by analyzing labeled data of previous borrowers to predict default probability.
Real-World Applications of Unsupervised Learning
- Customer Segmentation: Unsupervised learning clustering divides customers into groups with similar characteristics, enabling targeted marketing strategies without predefined segments.
- Anomaly Detection: Unsupervised learning algorithms identify unusual patterns in network traffic, financial transactions, or sensor data that deviate from normal behavior.
- Recommendation Systems: Unsupervised learning discovers latent patterns in user preferences and item characteristics, suggesting products users might enjoy based on similarity.
- Market Research: Unsupervised learning reveals natural customer preferences and product associations without predefined categories, informing business strategy.
- Data Preprocessing: Unsupervised learning techniques like dimensionality reduction simplify complex datasets, removing noise while preserving essential information.
When to Use Supervised Learning



Choose supervised learning when you have clearly defined prediction targets and access to labeled training data. If you need precise predictions with measurable accuracy, supervised learning algorithms deliver reliable results. Your use case demands supervised learning when outcomes are binary (spam/not spam), categorical (disease type), or continuous (price forecasts).
Supervised learning becomes essential when prediction accuracy is critical, such as in medical diagnosis or financial risk assessment. If you can afford the time and resources to create quality labeled datasets, supervised learning provides superior predictive performance.
When to Use Unsupervised Learning
- Unsupervised learning shines when you lack labeled data but possess an abundance of raw information. Choose unsupervised learning for exploratory analysis when the data structure is unknown and discovering patterns is the primary goal.
- Unsupervised learning algorithms suit scenarios where labeling would be prohibitively expensive or when you want to discover naturally occurring data groupings. Your problem calls for unsupervised learning when generating insights matters more than making specific predictions.
- Unsupervised learning excels in preprocessing steps where feature extraction or dimensionality reduction prepares data for subsequent analysis.
Advantages and Disadvantages Comparison
- Supervised Learning Advantages: High prediction accuracy, clear performance metrics, proven effectiveness for well-defined problems, direct feedback during training, and extensive algorithm availability.
- Supervised Learning Disadvantages: Requires extensive labeled data, is expensive and time-consuming for labeling, prone to overfitting, less adaptable to unexpected data patterns, and difficult to scale to complex, unstructured problems.
- Unsupervised Learning Advantages: Works with abundant unlabeled data, discovers unexpected patterns, requires minimal preprocessing, scales efficiently to large datasets, and reveals hidden insights.
- Unsupervised Learning Disadvantages: Lacks clear success metrics, difficult to validate results, computationally intensive, less intuitive interpretation, and requires domain expertise for evaluation.
Semi-Supervised Learning: The Middle Ground
- Semi-supervised learning combines elements of both approaches, leveraging limited labeled data alongside abundant unlabeled data. This hybrid methodology becomes valuable when labeling some data is feasible, but labeling everything is impractical.
- Semi-supervised learning techniques like self-training use model predictions as pseudo-labels for unlabeled data. Co-training employs multiple models that train each other. These approaches improve performance with minimal additional labeling, making them practical for real-world scenarios, balancing accuracy needs with resource constraints.
Challenges in Machine Learning Implementation
Supervised Learning Challenges: Creating quality labeled datasets demands substantial investment. Labeled data often contains human errors or inconsistencies. Models may overfit to training data, performing poorly on new examples. Continuous updates with new labeled data maintain accuracy as data distributions shift.
Unsupervised Learning Challenges: Evaluating algorithm output lacks objective benchmarks. Determining optimal cluster numbers or pattern validity requires interpretation. Models may identify statistically significant patterns lacking practical meaning. Computational demands increase with dataset size.
How to Choose Between Supervised and Unsupervised Learning
- Define Your Problem: Clearly articulate whether you need predictions (supervised) or pattern discovery (unsupervised). Identify if outcomes are known or unknown.
- Assess Data Availability: Evaluate whether labeled data exists and labeling expense is justified. Consider whether unlabeled data abundance makes unsupervised learning practical.
- Consider Resources: Supervised learning requires labeling resources, but a simpler computational infrastructure. Unsupervised learning demands powerful processors but avoids labeling costs.
- Evaluate Success Metrics: If you can define clear accuracy metrics, supervised learning fits. If discovering insights matters, unsupervised learning applies.
- Test Both Approaches: When uncertain, prototype both methods. Compare results against your specific objectives and constraints.
Future Trends in Machine Learning
The machine learning field continues evolving with emerging paradigms. Semi-supervised learning gains adoption as organizations recognize value in hybrid approaches. Self-supervised learning leverages data’s inherent structure for automatic labeling, reducing human annotation needs.
Transfer learning enables models trained on large datasets to solve new problems with minimal additional data. Reinforcement learning agents learn through environment interaction and reward feedback, powering autonomous systems and game-playing AI. These emerging approaches complement traditional supervised learning and unsupervised learning, offering practitioners more tools for solving diverse data challenges.
More Read: Best Machine Learning Courses for Beginners
Conclusion
Supervised learning and unsupervised learning represent two complementary approaches to solving different machine learning challenges. Supervised learning algorithms excel at prediction tasks when labeled data exists, delivering high accuracy for well-defined problems like fraud detection, disease diagnosis, and price forecasting. Unsupervised learning algorithms shine at discovering hidden patterns in unlabeled data, enabling customer segmentation, anomaly detection, and exploratory analysis.
The choice between supervised vs unsupervised learning depends on your specific problem definition, available data resources, and business objectives. Often, the most effective solutions combine both approaches—using unsupervised learning for initial data exploration and feature extraction, followed by supervised learning for precise predictions. Understanding these fundamental machine learning paradigms empowers organizations to leverage data effectively, extract meaningful insights, and make informed decisions in an increasingly AI-driven world. As machine learning continues evolving with semi-supervised and self-supervised approaches, mastering both traditional methods remains essential for modern data science professionals.