What Is Transfer Learning and When Should You Use It?
Discover transfer learning in machine learning. Learn what transfer learning is, when to use it, pre-trained models, fine-tuning techniques, and real.

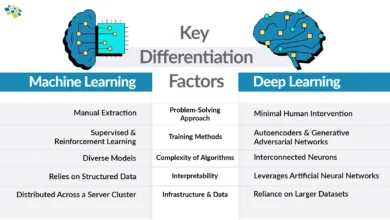
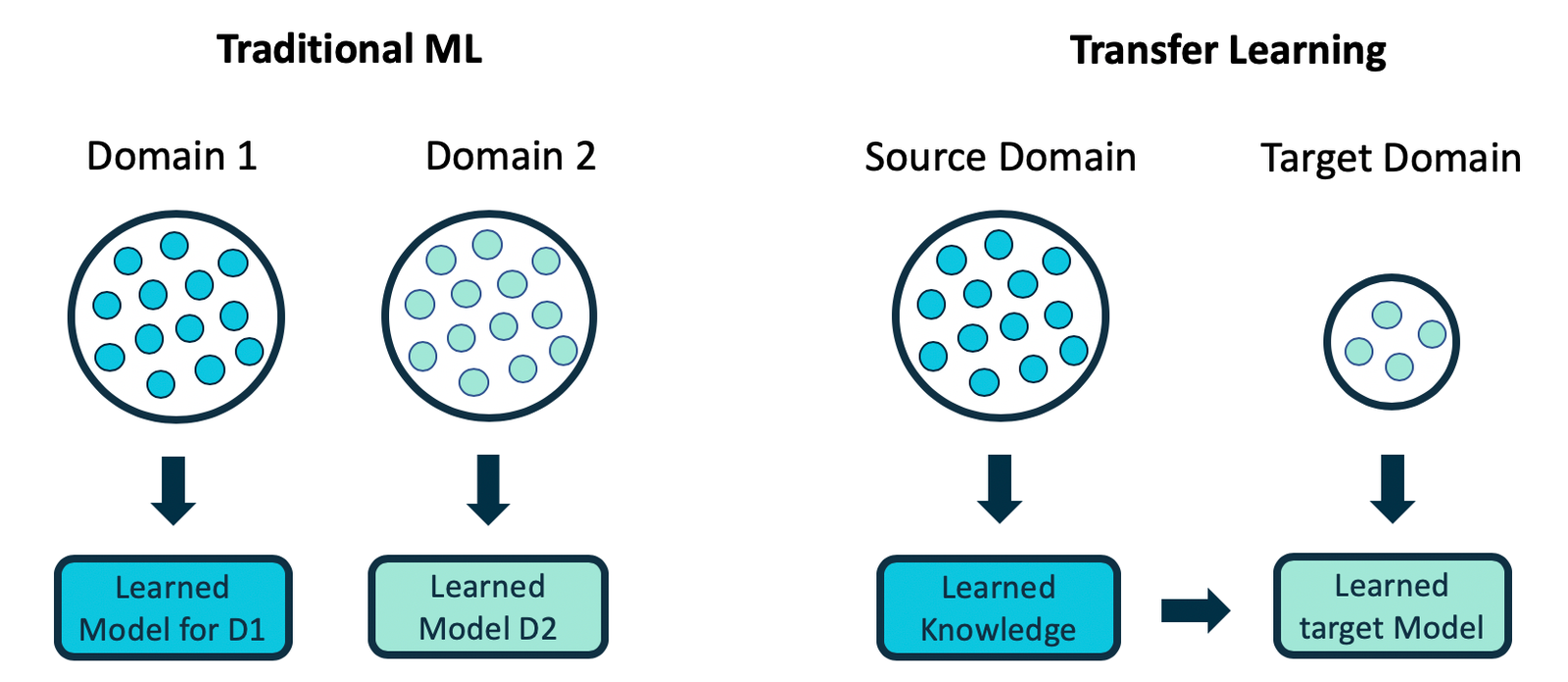
Transfer learning has emerged as one of the most powerful and transformative techniques in modern machine learning and deep learning. At its core, transfer learning is a methodology where knowledge acquired from training a model on one task is strategically reapplied to improve performance on a different but related task. Rather than training every model from scratch—a resource-intensive and time-consuming process—transfer learning allows practitioners to leverage pre-trained models that have already learned valuable feature representations from massive datasets.
This approach has revolutionized the field by democratizing access to sophisticated machine learning capabilities, enabling organizations and individuals to build high-performing systems even with limited data and computational resources. The significance of transfer learning in machine learning cannot be overstated, particularly in the domain of deep learning, where training neural networks from scratch demands enormous computational power and vast amounts of labeled training data.
Whether you’re working on computer vision tasks like image classification and object detection, or natural language processing applications such as sentiment analysis and machine translation, knowing when and how to apply transfer learning techniques is essential for achieving optimal results efficiently. This comprehensive guide explores the fundamentals of transfer learning, examines various transfer learning strategies, discusses the critical concept of fine-tuning pre-trained models, and provides practical insights into real-world applications where transfer learning delivers exceptional value.
What Is Transfer Learning
Transfer learning fundamentally changes how we approach machine learning problems by reusing knowledge from one domain for another.
Definition and Core Concept
Transfer learning is a machine learning technique in which a model trained on one task—called the source task—is repurposed as the starting point for a model on a second related task, known as the target task. The core principle involves taking learned features, weights, or knowledge from the source model and applying them to the target domain, thereby accelerating learning and improving generalization. Unlike traditional machine learning approaches that assume training and test data come from the same distribution, transfer learning explicitly bridges different but related domains.
The fundamental advantage lies in the fact that neural networks, particularly those trained on large-scale datasets like ImageNet, develop generalizable feature representations in their early and middle layers. These learned features—such as detecting edges, textures, and shapes in images—remain relevant across diverse visual recognition tasks, making them valuable for transfer.
Historical Context and Evolution
The concept of transfer learning isn’t entirely new, though its prominence in deep learning is relatively recent. Research into transfer learning in neural networks dates back to 1976 with foundational work by Bozinovski and Fulgosi. However, the field gained significant momentum in the early 2000s with multi-task learning research and formal theoretical frameworks. A pivotal moment came in 2016 when Andrew Ng remarked at NIPS that transfer learning would become the next major driver of machine learning commercial success after supervised learning—a prediction that has proven remarkably accurate. Today, transfer learning applications span countless domains, from healthcare diagnostics to autonomous vehicles, revolutionizing how organizations develop AI solutions.
Key Concepts: Pre-Trained Models and Feature Extraction
These fundamental building blocks are essential for effectively implementing transfer learning.


What Are Pre-Trained Models?
Pre-trained models are neural networks that have been previously trained on large datasets and are now saved with their learned weights and parameters intact. These models serve as the foundation for transfer learning approaches. The most common pre-trained model examples include ResNet, VGG, Xception, MobileNet, and BERT, each trained on massive datasets like ImageNet (containing 1.4 million images across 1,000 classes) or large text corpora. By utilizing pre-trained models, you avoid the computational expense and time required to train deep neural networks from scratch. These models have already learned fundamental patterns and feature representations that are applicable to numerous related tasks.
How Feature Extraction Works
In feature extraction, one of the primary transfer learning approaches, the pre-trained model is used as a fixed feature extractor without modifying its weights. The process involves removing the final output layer of the pre-trained model—which is task-specific—and attaching new layers customized for your specific problem. The earlier layers of the network remain frozen, preserving their learned knowledge while the new task-specific layers are trained from scratch on your dataset.
This method is particularly effective when you have limited training data, as you’re only training a small number of parameters while leveraging the rich feature representations already captured by the pre-trained network. Feature extraction in transfer learning offers significant computational savings and reduced overfitting risk by reducing the number of trainable parameters substantially.
Types of Transfer Learning: Different Approaches
Transfer learning manifests in several distinct forms, each suited to different scenarios and data availability situations.
Inductive Transfer Learning
Inductive transfer learning occurs when the source and target domains are identical, but the specific tasks differ. In this scenario, the pre-trained model possesses general expertise about domain features that apply directly to the target task. A practical example involves using a pre-trained image classification model trained on general object recognition to build a specialized model for medical image diagnosis. Inductive transfer learning is further subdivided into two categories: multi-task learning, where source domain data is labeled, and self-taught learning, where source domain data remains unlabeled. This approach works particularly well when you have a substantial pre-trained model relevant to your domain.
Transductive Transfer Learning
Transductive transfer learning applies when source and target domains differ, though they remain interrelated, with the target domain containing little or no labeled data. For instance, you might adapt a sentiment analysis model trained on product reviews to analyze movie reviews. This transfer learning strategy leverages patterns learned from the labeled source domain to make accurate predictions on the unlabeled target domain. Transductive transfer learning proves invaluable when obtaining labeled data for your specific domain is prohibitively expensive or time-consuming.
Unsupervised Transfer Learning
Unsupervised transfer learning operates when both source and target domains contain unlabeled data. The model identifies common underlying features in the unlabeled data to generalize effectively to new target tasks. This approach is essential in scenarios where labeled data is scarce across both domains, allowing models to discover fundamental patterns without explicit supervision.
Domain Adaptation and Heterogeneous Transfer Learning
Domain adaptation focuses on aligning source and target domain distributions, making transferred knowledge more applicable to new contexts. Heterogeneous transfer learning addresses scenarios where source and target feature spaces differ substantially, employing specialized techniques to bridge the gap between different feature representations and improve knowledge transferability.
When Should You Use Transfer Learning: Identifying Ideal Scenarios
Transfer learning isn’t universally appropriate; when to apply it is crucial for success.
Lack of Sufficient Training Data
The most compelling reason to employ transfer learning is when you lack adequate labeled training data for your specific task. Deep neural networks, particularly in computer vision and natural language processing, require enormous amounts of training data to learn effectively from scratch. Transfer learning circumvents this limitation by leveraging knowledge from models trained on massive datasets. If you have a small dataset (e.g., 1,000 images) but need to build an image classifier, transfer learning enables you to achieve strong performance by using features learned from models trained on millions of images.
Related Task with Available Pre-Trained Models
Transfer learning succeeds when pre-trained models exist for tasks related to your target problem. The relationship doesn’t need to be identical—it needs to share sufficient similarities in underlying features. For example, recognizing cars and trucks share low-level visual features like edges and shapes, making knowledge from car detection useful for truck detection. Conversely, transfer learning fails when source and target tasks are vastly dissimilar, as the learned features won’t generalize effectively.
Limited Computational Resources
Training large deep learning models demands significant computational power, often requiring GPU or TPU acceleration and days of processing time. Organizations with limited computational budgets benefit tremendously from transfer learning, which dramatically reduces training time and hardware requirements. Using a pre-trained model and fine-tuning specific layers requires far less computational overhead than training from scratch.
Need for Rapid Model Development
When time-to-market is critical, transfer learning accelerates development cycles substantially. Rather than spending weeks training custom models, practitioners can adapt pre-trained models to their specific needs within days or hours. This rapid prototyping capability has become increasingly valuable in competitive business environments.
Domain-Specific Applications with Limited Data
Specialized domains like medical imaging, autonomous vehicles, and rare disease detection often lack sufficient public datasets for training models from scratch. Transfer learning proves invaluable here—you leverage general-purpose models trained on broader datasets and fine-tune them for domain-specific nuances using your limited specialized data.
Fine-Tuning: The Core Transfer Learning Technique
Fine-tuning represents the most practical and widely used implementation of transfer learning principles.
Fine-Tuning Fundamentals
Fine-tuning involves taking a pre-trained model and continuing to train it on a new dataset, updating some or all of its weights to adapt the model to your specific task. Unlike simple feature extraction, which freezes all pre-trained weights, fine-tuning allows the model to modify learned representations to become more relevant to your target domain. The process typically involves unfreezing one or more layers in the pre-trained network and training them on your new data using a smaller learning rate than would be used when training from scratch. This careful approach preserves valuable learned knowledge while allowing gradual adaptation to new task requirements.
The Fine-Tuning Workflow
Fine-tuning follows a systematic process: First, select a pre-trained model architecture appropriate for your task. Second, remove or modify the final output layer to match your target classification problem. Third, freeze the earlier layers to preserve general feature learning. Fourth, train the new layers and optionally some deeper layers on your target dataset with a small learning rate. Fifth, gradually unfreeze deeper layers if performance permits, retraining with increasingly conservative learning rates. This hierarchical approach balances preserving learned knowledge with adaptation to new tasks.
Frozen Layers vs. Trainable Layers
In fine-tuning, frozen layers represent network components whose weights remain fixed during retraining, preserving previously learned features. Trainable layers or modifiable layers are network components that are updated during training to adapt the model’s knowledge to new, related tasks. The optimal balance between frozen and trainable layers depends on your dataset size, task similarity, and available computational resources. With very small datasets, more layers remain frozen; with larger datasets, more layers become trainable to enable greater adaptation.
Learning Rate Considerations in Fine-Tuning
A critical aspect of successful fine-tuning involves using an appropriately reduced learning rate. Since the pre-trained weights already contain valuable learned features, you want to update them gradually rather than dramatically. Typically, the learning rate for fine-tuning is 10-100 times smaller than when training layers from scratch. This conservative approach prevents the model from “unlearning” previously acquired knowledge while still allowing task-specific adaptation. Choosing the right learning rate for fine-tuning often determines the success or failure of your transfer learning effort.
Transfer Learning in Computer Vision
Computer vision represents perhaps the most successful domain for transfer learning applications.
Image Classification with Pre-Trained Models
Transfer learning in computer vision begins with image classification, where pre-trained models like ResNet-50, VGG-16, and MobileNet serve as foundation models. These architectures have learned rich feature hierarchies through training on ImageNet. By leveraging these models, practitioners can build accurate image classifiers for specialized tasks—identifying plant diseases, detecting product defects, or classifying medical imaging scans—using orders of magnitude less data than would be required for training from scratch.
Object Detection and Semantic Segmentation
Beyond classification, transfer learning techniques extend to object detection (identifying and locating multiple objects within images) and semantic segmentation (classifying each pixel in an image). Models like Faster R-CNN, YOLO, and Mask R-CNN all employ transfer learning strategies, using convolutional backbones pre-trained on ImageNet before specializing for detection and segmentation tasks. This approach has enabled significant advances in medical image analysis, autonomous driving, and industrial quality control.
Practical Example: Medical Image Analysis
A compelling real-world example involves medical imaging, where collecting and labeling thousands of images is expensive and requires expert annotation. Practitioners apply transfer learning by taking models pre-trained on general image datasets and fine-tuning them on available medical images to detect tumors, fractures, or other pathologies. This approach achieves diagnostic accuracy comparable to or exceeding human radiologists while requiring significantly less specialized training data.
Transfer Learning in Natural Language Processing
Natural language processing represents another transformative domain for transfer learning implementation.
Pre-Trained Language Models
Transfer learning in NLP has been revolutionized by powerful pre-trained language models like BERT, GPT, and ELMo. These models are pre-trained on enormous text corpora using objectives like predicting masked words or next-sentence prediction, learning deep semantic and syntactic representations. Organizations then fine-tune these foundational models for downstream tasks like sentiment analysis, text classification, named entity recognition, and machine translation.
Word Embeddings and Semantic
Pre-trained word embeddings like Word2Vec, GloVe, and FastText capture semantic relationships between words learned from massive text corpora. These embeddings provide substantial improvements over random initialization when building NLP models on limited data, essentially transferring knowledge about language structure and meaning.
Practical Applications: Sentiment Analysis
Transfer learning in sentiment analysis involves taking a language model pre-trained on general text and fine-tuning it to understand sentiment in specific domains—product reviews, social media, customer feedback. The pre-trained model already understands language structure and basic semantics; fine-tuning teaches it domain-specific sentiment patterns much more efficiently than training from scratch.
Advantages and Benefits of Transfer Learning
Transfer learning delivers substantial benefits that justify its widespread adoption across industries.
Significantly Reduced Training Time
By starting with a pre-trained model rather than training from scratch, you eliminate weeks or months of computational effort. A task that might require 30 days of GPU training from scratch could be fine-tuned in 2-3 days using a pre-trained model. This dramatic acceleration enables rapid prototyping and iteration.
Superior Performance with Limited Data
Transfer learning allows building high-performing models with smaller datasets than would be viable without it. The transferred knowledge compensates for limited data availability, producing models that generalize better and avoid overfitting to small datasets. This is particularly valuable in specialized domains where data collection is expensive.
Reduced Computational Requirements
Fine-tuning requires substantially less computational power than training deep networks from scratch. You can train pre-trained models on standard GPUs or even CPUs in many cases, democratizing access to advanced machine learning techniques and reducing energy consumption and environmental impact.
Enhanced Model Generalization
Models trained through transfer learning often generalize better to new, unseen data compared to models trained exclusively on small datasets. The broad feature representations learned from large-scale pre-training improve the model’s ability to recognize patterns that apply beyond the specific training set.
Access to State-of-the-Art Architectures
Transfer learning provides access to cutting-edge model architectures developed by leading research organizations and trained on massive resources. Rather than designing novel architectures from scratch, practitioners can directly benefit from advances in deep learning research.
Challenges and Limitations of Transfer Learning
Despite numerous advantages, transfer learning has notable limitations that practitioners must understand.
Domain Mismatch and Negative Transfer
When source and target domains differ substantially, transfer learning can perform worse than training from scratch—a phenomenon called negative transfer. Features learned on medical images may not transfer effectively to natural scene images. Careful consideration of task similarity is essential before committing to transfer learning.
Overfitting During Fine-Tuning
Fine-tuning pre-trained models on small datasets can lead to overfitting, where the model memorizes training data rather than learning generalizable patterns. Using conservative learning rates, data augmentation techniques, and proper regularization helps mitigate this risk.
Feature Space Mismatch
Heterogeneous transfer learning challenges arise when source and target feature spaces differ significantly, creating incompatibilities in how features are represented and processed. Addressing these mismatches requires sophisticated domain adaptation techniques.
Computational Complexity of Fine-Tuning
While less demanding than training from scratch, fine-tuning large models still requires significant computational resources, especially when unfreezing multiple layers for complete model adaptation. Parameter-efficient fine-tuning techniques like LoRA (Low-Rank Adaptation) help address this limitation.
Unclear Feature Relevance
Sometimes it’s unclear which layers’ features transfer effectively to your target task. Features that work well for general object recognition might not help with subtle visual distinctions (like determining if a door is open or closed). Experimentation and analysis are often required to identify optimal layer transfer strategies.
Transfer Learning Strategies and Best Practices
Implementing transfer learning effectively requires strategic decision-making.
Selecting Appropriate Pre-Trained Models
Choose pre-trained models trained on datasets similar to your target domain. Computer vision tasks benefit from models pre-trained on ImageNet or specialized datasets like COCO; NLP tasks leverage models pre-trained on large text corpora. Consider model size (larger models often transfer better but require more resources) and architecture compatibility with your infrastructure.
Determining the Right Number of Frozen Layers
The optimal number of frozen vs. trainable layers depends on your specific situation. With abundant target data (similar quantity to the original training data), unfreeze most layers. With limited target data, freeze most layers and train only the final few. With very limited data, use feature extraction with completely frozen weights.
Implementing Progressive Unfreezing
Progressive unfreezing involves initially freezing all pre-trained layers, training the new task-specific layers, then gradually unfreezing deeper pre-trained layers and retraining with small learning rates. This cautious approach often outperforms simultaneously unfreezing many layers.
Applying Data Augmentation Techniques
Enhance limited training data through data augmentation—applying random but realistic transformations like rotation, flipping, and color jittering to training images. Augmentation increases effective training data quantity and improves model robustness.
Monitoring and Validation During Fine-Tuning
Continuously monitor model performance on a validation set during fine-tuning. Stop training when validation performance plateaus to avoid overfitting. Use techniques like early stopping and learning rate reduction to optimize training dynamics.
Real-World Applications and Success Stories
Transfer learning enables numerous practical applications across industries.
Medical Imaging and Diagnostics
Healthcare organizations apply transfer learning to detect diseases in medical imaging. Models pre-trained on general images are fine-tuned to identify tumors in mammograms, lesions in MRI scans, and fractures in X-rays, often approaching radiologist-level accuracy with significantly less training data than traditional approaches require.
Autonomous Vehicles and Self-Driving Technology
Self-driving vehicle development leverages transfer learning extensively. Object detection models pre-trained on general datasets are adapted for detecting pedestrians, vehicles, and traffic signals. This approach accelerates development while improving safety through robust object recognition.
Natural Language Processing and Text Analysis
Businesses use transfer learning to build sentiment analysis systems for customer feedback, content moderation systems for user-generated content, and question-answering systems for customer service automation. Pre-trained language models dramatically reduce development time and required training data.
E-Commerce and Product Recommendations
E-commerce platforms apply transfer learning to build product recommendation systems, visual search engines, and product classification systems that learn from limited labeled data by leveraging models pre-trained on vast image and text datasets.
Financial Services and Fraud Detection
Financial institutions apply transfer learning to fraud detection and credit risk assessment by adapting models trained on general financial data patterns to institution-specific transaction patterns with minimal additional labeled data.
Also Read: Best Robotics Kits for Learning and Hobby Projects
Conclusion
Transfer learning has fundamentally transformed machine learning by enabling practitioners to build high-performing models with limited data, computational resources, and time. By leveraging pre-trained models developed through massive-scale training efforts and strategically applying fine-tuning techniques, organizations across industries achieve results that would be infeasible with traditional approaches. Transfer learning should be your default strategy when related pre-trained models exist, target domain data is limited, or computational resources are constrained.
The technique excels in computer vision and natural language processing domains where pre-trained models are readily available and transfer effectively. However, success requires careful consideration of domain similarity, strategic decisions about which layers to freeze and train, and disciplined fine-tuning practices that preserve valuable learned knowledge while enabling task-specific adaptation. As deep learning models grow larger and more powerful, transfer learning becomes increasingly important for democratizing access to advanced AI capabilities, enabling organizations of all sizes to harness machine learning’s transformative potential.